Как добиться качества сравнимого с ChatGPT от доступных языковых моделей?

Хотя модели серии GPT, такие как ChatGPT и GPT-4, очень мощные, они вряд ли когда-нибудь будут полностью открытыми. К счастью, сообщество разработчиков с открытым исходным кодом прилагает все усилия для решения этой проблемы.
Например, компания Meta* выложила (слила?) в открытый доступ модели семейства LLaMA, в которых количество параметров варьируется от 7 до 65 миллиардов. Модель с 13 миллиардами параметров может превзойти модель GPT-3 с 175 миллиардами параметров в большинстве эталонных тестов. Однако, поскольку в ней нет этапа настройки (файнтюна), её фактические результаты работы "неудовлетворительны".
Стэнфордская модель Alpaca генерирует обучающие данные самоинструктируемым (self-instructed) способом, обращаясь к API OpenAI. Имея всего 7 миллиардов параметров, эта лёгкая модель может быть точно донастроена за небольшие деньги для достижения производительности и качества, аналогичной очень большой языковой модели, такой как GPT-3.5 с 175 миллиардами параметров.
Однако существующие решения с открытым исходным кодом можно рассматривать только как модели с тонкой настройкой (файнтюном) под наблюдением (supervised fine-tuned) на первом этапе RLHF* (Reinforcement Learning from Human Feedback), при этом последующие этапы выравнивания и файнтюна не выполняются. Кроме того, набор обучающих данных Alpaca ограничен английским языком, что в некоторой степени ограничивает производительность модели.
RLHF - в машинном обучении обучение с подкреплением на основе человеческой обратной связи (RLHF) или обучение с подкреплением на основе человеческих предпочтений - это метод, который обучает "модель вознаграждения" непосредственно на основе человеческой обратной связи и использует эту модель в качестве функции вознаграждения для оптимизации политики агента с помощью обучения с подкреплением (RL) через алгоритм оптимизации, например, Proximal Policy Optimization.
Тем не менее, впечатляющие результаты ChatGPT и GPT-4 объясняются внедрением RLHF в процесс обучения, что повышает согласованность генерируемого контента с человеческими ценностями.
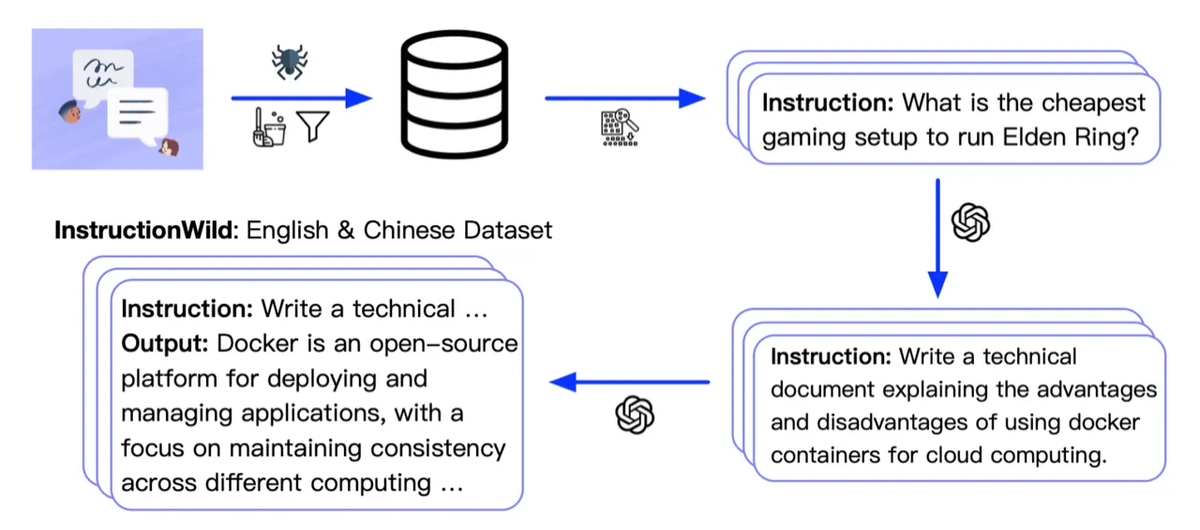
Разработчики ColossalChat выпустили двуязычный набор данных, включающий около 100 000 пар вопросов и ответов на английском и китайском языках. Набор данных был собран и очищен из реальных сценариев вопросов на платформах социальных сетей, которые послужили исходным набором данных, и был расширен с помощью технологии self-instruct, а затраты на аннотацию составили около 900 долларов.
По сравнению с наборами данных, созданных другими методами самообучения, этот набор данных содержит более реалистичные и разнообразные исходные данные и охватывает более широкий круг тем. Набор данных подходит как для файнтюна, так и для обучения RLHF. Благодаря предоставлению высококачественных данных, обученная на таком датасете модель, может достичь лучшего диалогового взаимодействия, а также поддержать китайский язык.
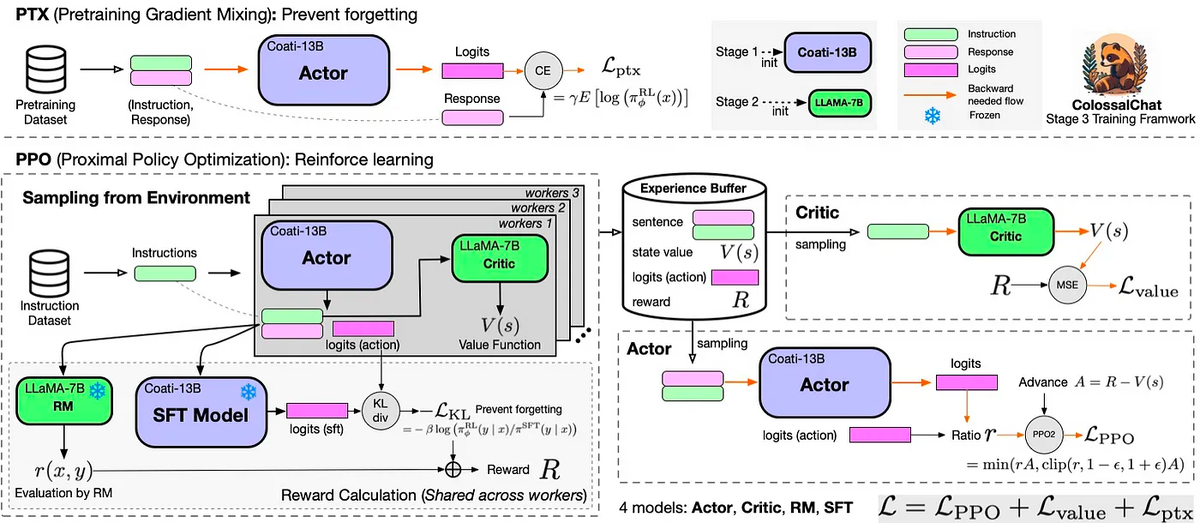
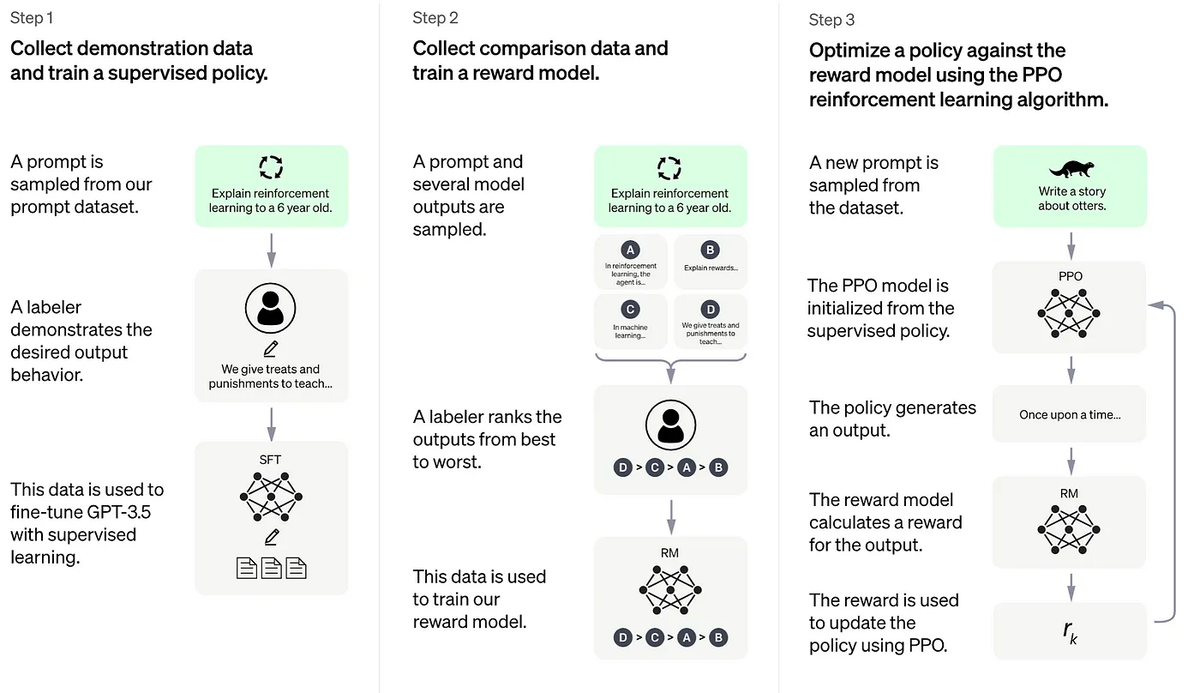
Репликация алгоритма RLHF включает три этапа:
На первом этапе RLHF выполняется контролируемая тонкая настройка инструкций с использованием ранее упомянутых наборов данных для тонкой настройки модели.
На RLHF-этапе2 модель вознаграждения обучается присваивать соответствующие баллы путем ручного ранжирования различных выходов для одной и той же подсказки, которая затем контролирует обучение модели вознаграждения.
В RLHF-Stage3 используется алгоритм обучения с подкреплением, который является наиболее сложной частью процесса обучения: