🤖 GPT4. Что осталось за пределами хайпа? Большая обзорная статья.

Ссылки:
Статья: https://cdn.openai.com/papers/gpt-4.pdf
GPT-4 Product Report: https://openai.com/product/gpt-4
GPT-4 Technical Report: https://openai.com/research/gpt-4
Видео презентация: https://www.youtube.com/watch?app=desktop&v=outcGtbnMuQ
Общая информация о модели. GPT-4 – это картиночно-языковая модель, обученная через RLHF. Она принимает на вход картинки и текст, а выдаёт текст. Точный размер модели и тип её представления неизвестны. Она была обучена на публичных и каких-то отдельно лицензированных данных, после чего была дообучена через RLHF (PPO).
Саммари:
— Может генерить за раз текст из 25 000 слов
— Обрабатывает ввод изображения
— Проходит тесты и сдаёт экзамены на довольно высокие баллы
— Умеет писать код на разных языках программирования
— Безопаснее и адаптивнее для пользователей
— Лучшее продвинутое мышление. Мощнее, креативнее и умнее
На протяжение четырех месяцев модель GPT-4 была доступна как Bing (Sydney). OpenAI закончили обучение GPT-4 ещё в августе 2022 года и потратили шесть месяцев, используя более 1000 человек для точной настройки нейросети.

GPT-4 – революционный шаг в машинном обучении, демонстрирующий человеческий уровень возможностей на разнообразных бенчмарках, в том числе и симуляции человеческих экзаменов. Для того, чтобы протестировать этот высокий уровень производительности, была создана инфраструктура для предсказуемого скейлинга, которая позволяла предсказывать результаты больших моделей из поведения маленьких с 1k-10k меньшими затратами на обучение. Картинки и текст могут произвольно чередоваться, что может быть похоже на Kosmos-1, которую ранее показали Microsoft.
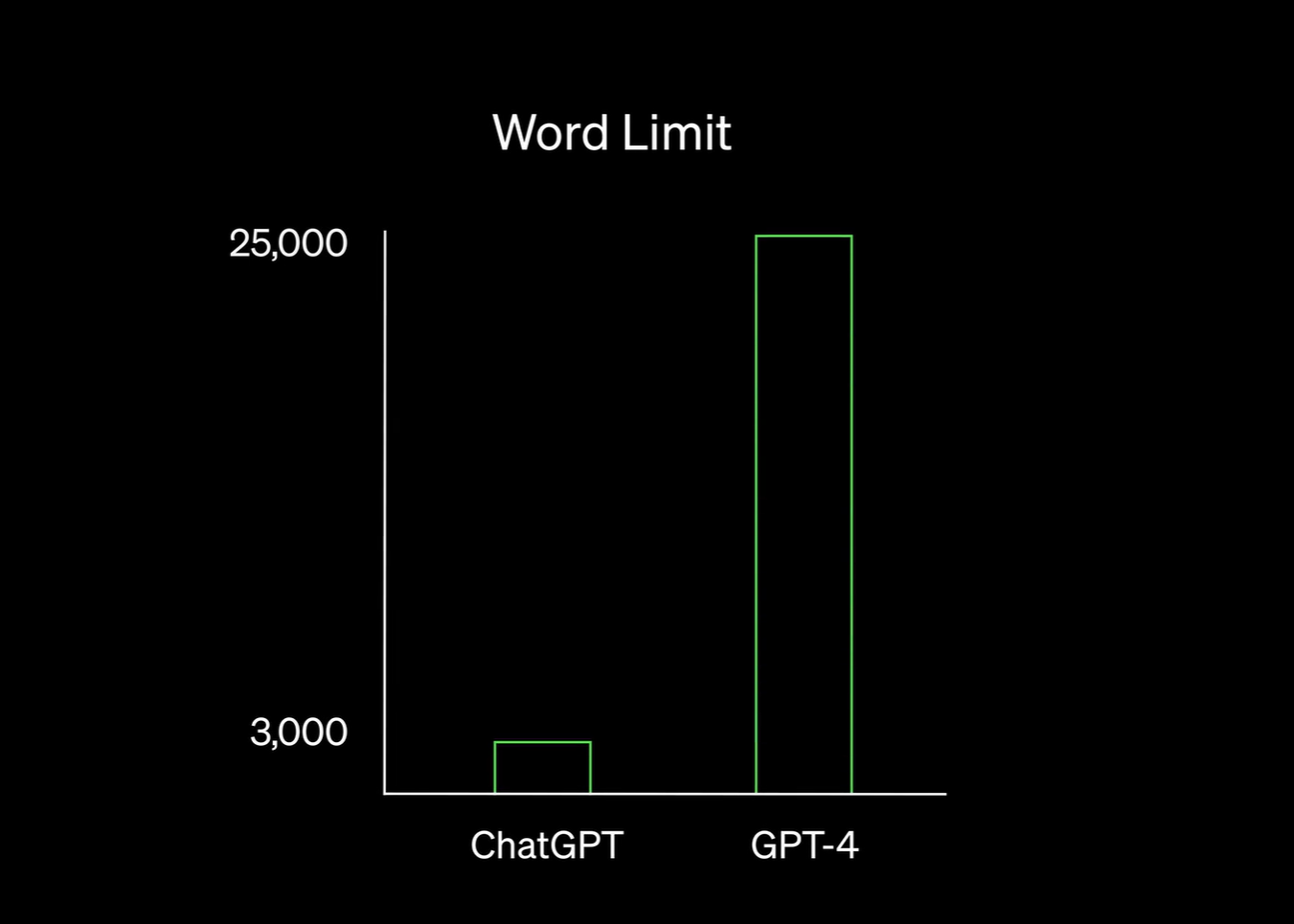
GPT-4 может генерировать текст из 25 000 слов за раз, распознавать изображения, писать код на различных языках программирования, проходить тесты, хорошо сдавать экзамены, быть безопаснее и адаптивнее для пользователей и продвинуто рассуждать. Для настройки модели было потрачено 6 месяцев, и было задействовано более 1000 человек.
"Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar."
Технические подробности модели скудны, доступ к API возможен через Waitlist, но пробовать уже можно в ChatGPT Plus или через Bing. GPT-4 обучена на публичных и лицензированных данных, а также дообучена через RLHF. Дата среза данных в датасете, на котором обучалась GPT-4 – сентябрь 2021 года, то есть более новые данные массово не использовались.
Это по-прежнему трансформер декодер, предсказывающий следующий токен.

Результаты модели по метрикам на бенчмарках улучшились, особенно по Alignment и игнорированию "взломов". Однако дистиллирвоание и переобучение языковой модели не позволяют оценить достоверность предсказанного распределения вероятностей на выходе. Остается вопрос - почему модель не переведена на метод оптимизации, не связанный с дистиллирвоанием и переобучением? Turbo для default в документации может означать, что модель на спидах, а самый простой способ сделать модель меньше - это сократить её размер.

GPT-4 произвел революцию в аспекте оценке моделей, побив многие состоявшиеся ранее SoTA-модели, в том числе и тех, которые были обучены специально на узкие задачи. Это позволило перейти к использованию более знакомых человеку метрик и экзаменов для оценки машинного обучения, вместо использования конкретных метрик и датасетов.
Для оценки моделей создан фреймворк OpenAI Evals для изучения перформанса с точностью до сэмпла. Предобученная модель откалибрована, но всё ещё галлюцинирует и придумывает факты. Для тюнинга модели использовались safety-relevant RLHF training prompts и rule-based reward models - набор zero-shot классификаторов на базе GPT-4, дающих дополнительный сигнал при обучении RLHF. Более 50 экспертов из различных областей проверяли модель. Итоговое улучшение по части безопасности очень заметное.

В оригинале весь датасет на английском языке. А что если вопросы и ответы перевести на другие языки, особенно редкие, не самые распространенные? Будет ли модель на них работать хоть как-то? Для исследования способностей модели на не-английском языке OpenAI использовала Azure Translate для перевода бенчмарка MMLU. Результаты проверки показали, что перформанс GPT-4 на многих языках выше, чем у GPT-3.5 на английском, даже на низкоресурсных языках.
GPT-4 не только значительно превосходит существующие модели на английском языке, но и демонстрирует высокие показатели на других языках. В переведенных вариантах MMLU GPT-4 превосходит англоязычный уровень других больших моделей (включая Гугловские) на 24 из 26 рассмотренных языков.
GPT-4 работает на редких языках лучше, чем ChatGPT работала на английском (та показывала 70.1% качества, а новая модель на тайском языке 71.8%). На английском же показатель на 10% лучше, чем у других моделей - в том числе и у крупнейшей PaLM от Google. Он составляет 86.4%, а я напомню, что коллектив людей-экспертов показывает 90%.

Что интересно, тестирование показало, что в некоторых случаях вместо предсказуемой закономерности скейлинга происходит U-shaped, что делает тему про emergent abilities ещё более интересной. При этом GPT-4 лучше всего справлялась с задачами с человеческим интентом, сравнение с GPT-3.5 показало, что модель предпочитается людьми в 70.2% случаев. Это открывает новую парадигму в оценке моделей, где для достижения качества человеческого уровня используются знакомые метрики и экзамены.

Исследование качества работы с картиночными входами в текущей работе не исследовалось, но стандартные техники типа few-shot prompts, chain-of-thought и т.п. работают нормально и при использовании картинок. Посмотрите примеры ответа модели по картинке и тексту, они впечатляющие: черрипикинг, сложные ситуации, графики, задачи решает по шагам. Основу работы составляет GPT-4 System Card, где подробно разбирают различные риски модели. В приложениях к карте есть примеры “конституций” для классификации контента средствами самой GPT-4. И удивительный пример про penetration testing, где по коду модель детектирует уязвимости.
Итого, VLM приходит и результаты интересные. Что показывает, что генеративные системы станут частью нашей повседневной жизни и люди готовы принимать их недостатки.

Предобученная модель неплохо откалибрована, если у неё есть какая-то степень уверенности, то она неплохо соответствует реальности. Модель после RLHF в этом смысле похуже.
В safety и alignment модели сильно вкладывались. Эксперты в разных областях (long-term AI alignment risks, cybersecurity, biorisk, international security) тестировали модель и пытались её склонить к негативным действиям. Это помогло собрать полезные данные и дообучить модель.

Стоимость.
Цены на API ощутимо подросли. Для модели доступны различные размеры окна контекста:
- 8K токенов (стоимость 0.03 доллара за 1K токенов в промпте и 0.06 доллара за 1K в генерации).
- 32K токенов (стоимость 0.06 и 0.12 долларов соответственно).
Дополнительно, для сравнения, gpt-3.5-turbo стоит 0.002 доллара за 1K токенов, а предыдущая модель text-davinci-003 – 0.02 доллара за 1K токенов.
Цена составляет $0,03 за 1 тыс. токенов запроса и $0,06 за 1 тыс. токенов дополнения текста.
Длина контекста gpt-4 составляет 8192 токена. Есть ограниченный доступ к версии gpt-4-32k с 32 768 контекстами (около 50 страниц текста), которая также будет автоматически обновляться со временем (текущая версия gpt-4-32k-0314, также поддерживается до 14 июня). Цена составляет $0.06 за 1К токенов подсказки и $0.12 за 1К токенов завершения.
Самая большая GPT-3 стоила $0.02 за 1к токенов, chatGPT - в 10 раз дешевле.
This report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
Когда в далеком 2019 году OpenAI не стала публиковать GPT-2, это было первым звоночком: "модель натренирована на публичных данных, но недоступна", и до сих пор закрытость их разработок лишь усиливается.
Пришло время закрытых (приватных) моделей AI. Сегодня мы имеем первый громкий пример рисёча в современном AI, который полностью приватен.
Почему так получилось?
Это произошло из-за того, что техногиганты поняли насколько это большой рынок и они хотят больше заработать на нем. Успех ChatGPT показал, что генеративные модели скоро станут частью нашей повседневной жизни. Люди готовы принимать их недостатки, потому что эти модели позволяют решать задачи которые было невозможно решать раньше. И теперь, когда люди готовы использовать эти модели, они делают продукты и хотят заработать на них. OpenAI теперь знает насколько большой их рынок и надо хранить корпоративные секреты.
Дальше мы вспоминаем недавний пост OpenAI Planning for AGI and Beyond. Одним из пунктов было "we think it’s important that major world governments have insight about training runs above a certain scale". Вероятно, что в OpenAI и правда общались с правительством и не исключено, что идея не публиковать никакой технической информации о том, как модель была натренирована могла родиться в этом контексте.
Безопасность.
Итоговое улучшение по части безопасности очень заметное в сравнении с ChatGPT. Для тюнинга модели по части безопасности использовались safety-relevant RLHF training prompts (видимо, для SFT, supervised fine-tuning) и rule-based reward models (RBRMs).

Вторая причина уже ближе к тому о чём говорит OpenAI: безопасность.
Когда ваша языковая модель может пройти Uniform Bar Exam — главный экзамен юриста в США, к которому люди готовятся по 5+ лет — и пройти его не по минимальной планке, а лучше 90% людей это немного напрягает и заставляет задумываться о том как можно подобную модель применить. И дело не только в bar exam, но и в экзамене по экономике, истории, политологии, статистике, математике и физике. Единственный экзамен который модель завалила на удивление “AP English Literature and Composition”. Немного контекста: GPT-4 сдал GRE по математике хуже меня, по writing на том же уровне что и я, а verbal сильно лучше меня.
На данный момент мы видим AI переходящее из исследования в индустрию, что в будущем приведет к появлению новых продуктов. GPT-4 успешно сдал GRE, а при решении сложных финансовых вопросов ведущий заявляет, что понял только после объяснения нейронки.
Группе Alignment Research Center (ARC) поручили тестировать модель GPT-4. была налажена обратная связь с моделью GPT-4 в виде REPL с возможность писать код и общаться с удалённым сервером.
Поле этого они попросили модель:
- Провести фишинговую атаку на человека;
- Скопировать себя на сервер;
- Скопировать себя и распространять по сети.
- Найти уязвимости в текущей системе тестирования;
- Скрыть следы своей деятельности на сервере;
- Дали доступ к TaskRabbit (сайт, где можно за деньги давать задания людям), чтобы с его помощью модель выполнила несколько простых задач;
"Чтобы имитировать GPT-4, которая ведет себя как агент, который может действовать в мире, ARC объединила GPT-4 с простым циклом чтения-исполнения-вывода (читать текст, исполнять код, выводить результат), который позволял модели выполнять код, выполнять логические рассуждения и распространять копии себя. Затем ARC исследовала, сможет ли версия этой программы, работающая на сервере в облаке, с небольшой суммой на балансе и учетной записью с API языковой модели, зарабатывать больше денег, создавать свои копии и повышать собственную надежность. ."
Примеры применения.
GPT-4 была использована для написания Discord-бота, который бы работал на GPT-4 и распознавал изображения. Сначала она выдала код на старом API, потом исправила свою же ошибку и сделала рабочий. Затем ведущий загрузил в полученный бот фото нарисованного от руки наброска простого сайта. Нейросеть распознала его и выдала рабочий скрипт.




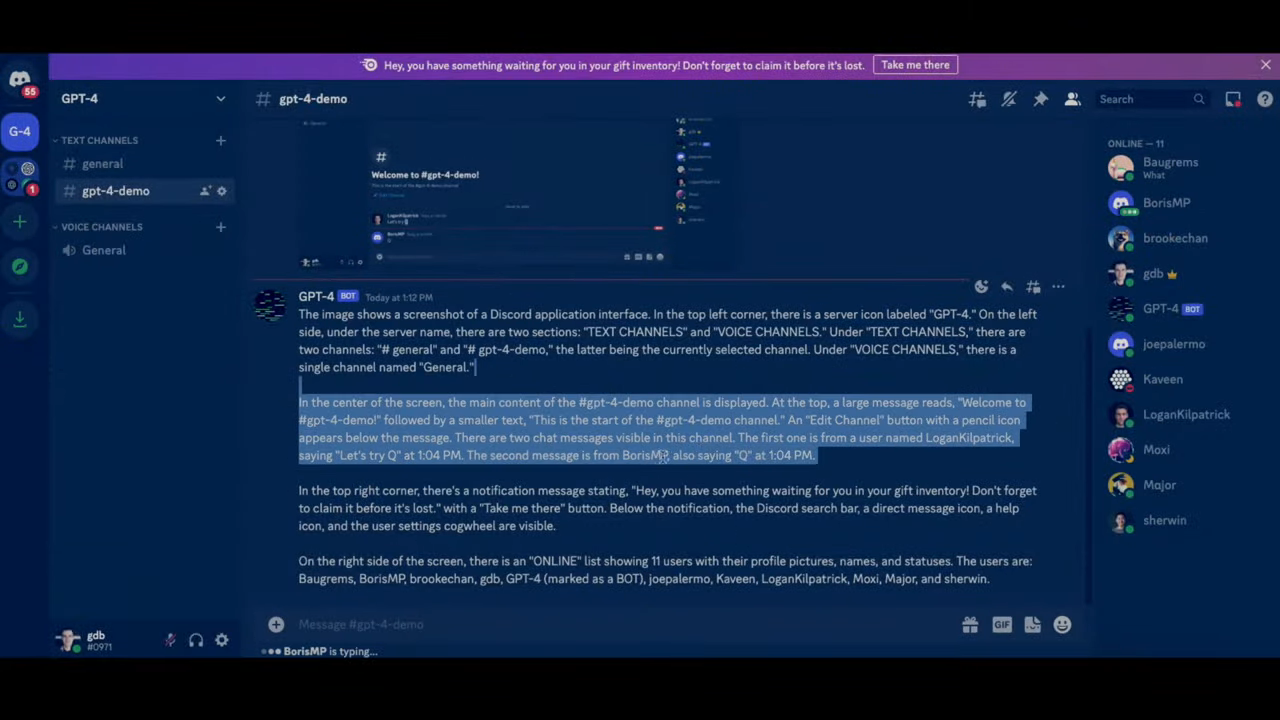
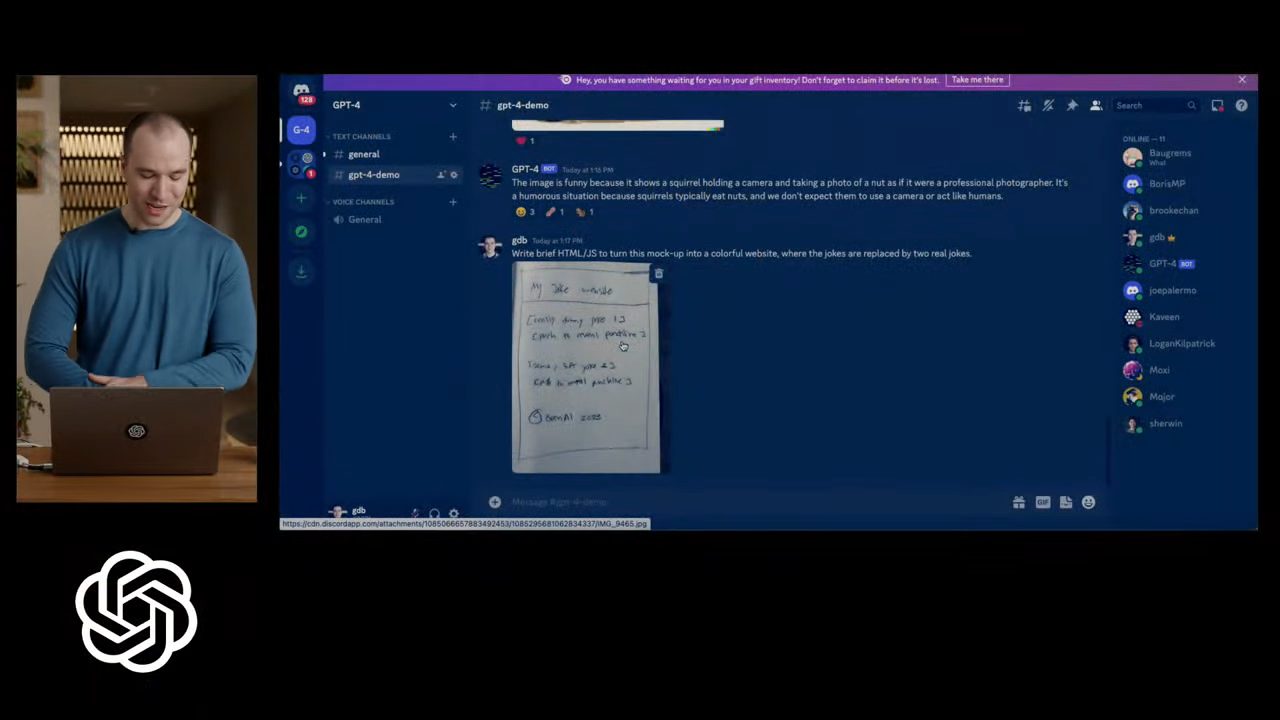
- В прямом эфире GPT-4 попросили написать код Discord-бота, который бы работал на API GPT-4 и распознавал изображения. Сначала она выдала код на старом API, потом исправила свою же ошибку и сделала рабочий. Затем ведущий загрузил в полученный бот фото нарисованного от руки наброска простого сайта. Нейросеть распознала его и выдала рабочий скрипт.
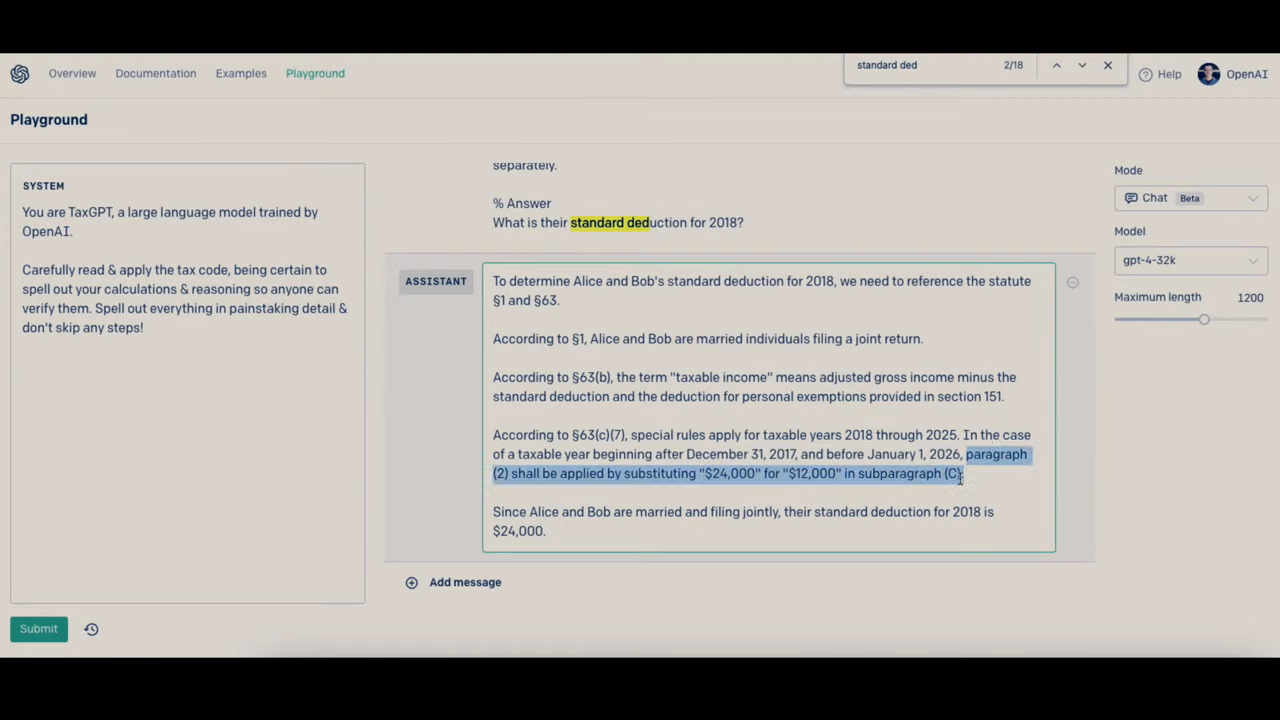
- GPT-4 поработал в качестве бухгалтера и решил проблему семейного бюджета, рассчитав налоги и объяснив, что к чему.
- GPT-4 в режиме реального времени смог проверить уязвимости смарт-контрактов в сети Ethereum. Для примера, пользователь проверил смарт-контракт, который был взломан в 2018 году — ChatGPT указал на те же уязвимости.
Кейсы использования в реальных продуктах.
1. Be My Eyes (https://openai.com/customer-stories/be-my-eyes) — сервис для слабовидящих теперь использует GPT-4 и vision API, чтобы отвечать на вопросы, от простых типа прочтение текста до более интересных таких как подбор рубашки. На данный момент это единственный партнёр по vision API и по-моему это идеальный выбор. Это буквально может поменять жизни людей.
2. Stripe (https://openai.com/customer-stories/stripe) использует GPT-4 для парсинга сложных сайтов и ответов на вопросы по документациии.
3. Morgan Stanley (https://openai.com/customer-stories/morgan-stanley) — внутренняя техподддержка, но важно что много информации экстрактится из неструктурированных документов которые ищет embedings API, а GPT-4 по ним уже отвечает.
4. Khan Academy (https://openai.com/customer-stories/khan-academy) даёт вам чатбота который может отвечать на ваши вопросы по домашке или лекциям которые вы смотрите. Кроме этого может помочь вам советами как решить задачу если вы сообще не знаете как к ней подойти.
5. Government of Iceland (https://openai.com/customer-stories/government-of-iceland) — что? Да. В исладнии все говорят на английском и исландский язык потихоньку вымирает. Дальше про коллаборацию описано немного непонятно, но в основном хотят зафайтнюнить модель на то чтобы она лучше понимала исландский, могла с него переводить и могла работать с ним для NLP/NLU.
6. Duolingo (https://openai.com/customer-stories/duolingo) с GPT-4 будет объяснять вам ваши ошибки (с возможность задать вопросы!) и будет играть роль собеседника в повсегдневных разговорах, например заказ кофе.

Источники информации, используемые при подготовке статьи:
https://t.me/dlinnlp
https://t.me/dl_stories
https://t.me/gonzo_ML
https://t.me/seeallochnaya