Разбираемся с доступными большими языковыми моделями (LLaMA, Alpaca. GPT4All, Vicuna, Koala и др.)

Список актуальных доступных языковых моделей постоянно расширяется и в их форках и модификациях можно запутаться. Здесь я планирую собрать и структурировать всю информацию о LLM. Данная статья будет обновляться по мере появления новых моделей.
Согласно информации в репозиториях к моделям, вы можете запускать их на ПК с ограниченной конфигурацией. На данный момент лично я протестировал следующие модели на ПК с 128 Гб оперативной памяти и без использования GPU. Еще один хороший способ опробовать эти модели - Google Colab Pro+, который поставляется с 50+ Гб оперативной памяти:
Для большинства людей лучшим вариантом будет llama.cpp, поскольку он поддерживает многие модели семейства LLaMA, хорошо оптимизирован, поддерживается сообществом и работает на устройствах со скромными характеристиками:
Список представляет собой продолжающуюся работу, в которой я пытаюсь сгруппировать их по семействам моделей (Foundation Models), и как они развиваются:
- BLOOM, BLOOMz от BigScience;
- Cerebras-GPT, GPT-J, GPT-NeoX, Polyglot и Pythia от EleutherAI;
- Flamingo и FLAN от Google;
- LLaMA, Alpaca, GPT4All, Vicuna и XGLM, OPT от Meta;
- RWKV.
Alpaca / LLaMA
Stanford Alpaca: An Instruction-following LLaMA Model.
- вебсайт LLaMA: Introducing LLaMA: A foundational, 65-billion-parameter language model (facebook.com)
- вебсайт Alpaca: https://crfm.stanford.edu/2023/03/13/alpaca.html
- Alpaca репозиторий GitHub: https://github.com/tatsu-lab/stanford_alpaca
- Коммерческое использование: Нет
Далее представлен список форков с модификацией, основанных на проекте LLaMA или Stanford Alpaca компании Meta:
Alpaca.cpp
Позволяет запускать быструю ChatGPT-подобную модель локально на вашем устройстве.
- репозиторий GitHub: antimatter15/alpaca.cpp: Locally run an Instruction-Tuned Chat-Style LLM (github.com)
Alpaca-LoRA
Репозиторий содержит код для воспроизведения результатов Stanford Alpaca с использованием низкоранговой адаптации (LoRA). Мы предоставляем модель Instruct, сходную по качеству с text-davinci-003, которая может работать на Raspberry Pi (для исследований), а код легко расширяется до моделей 13b, 30b и 65b.
- репозиторий GitHub: tloen/alpaca-lora: Instruct-tune LLaMA on consumer hardware (github.com)
- Demo: Alpaca-LoRA — a Hugging Face Space by tloen
Baize
Baize - это ChatGPT-подобная модель с открытым исходным кодом, доработанная с помощью LoRA. Она использует 100 тыс. диалогов, созданных с помощью ChatGPT через общение самой с собой. Также используются данные Alpaca для улучшения ее производительности. Доступны модели: 7B, 13B и 30B.
- репозиторий GitHub: project-baize/baize: Baize is an open-source chatbot trained with ChatGPT self-chatting data, developed by researchers at UCSD and Sun Yat-sen University. (github.com)
- Документ: 2304.01196.pdf (arxiv.org)
Cabrita
Португальская дообученная на инстркуция модель семейства LLaMA
- репозиторий GitHub: https://github.com/22-hours/cabrita
Chinese-Vicuna
Дообученная на инструкциях на китайском языке модель семейства LLaMA
- репозиторий GitHub: Facico/Chinese-Vicuna: Chinese-Vicuna: A Chinese Instruction-following LLaMA-based Model — — 一个中文低资源的llama+lora方案,结构参考alpaca (github.com)
GPT4All
Демка, данные и код для обучения большой языковой модели в стиле ассистента ChatGPT-like с ~800k GPT-3.5-Turbo Generations на основе LLaMa.
- репозиторий GitHub: nomic-ai/gpt4all: gpt4all: a chatbot trained on a massive collection of clean assistant data including code, stories and dialogue (github.com)
- репозиторий GitHub: nomic-ai/pyllamacpp: Official supported Python bindings for llama.cpp + gpt4all (github.com) (биндинг к llama.cpp)
- Обзор: Is GPT4All your new personal ChatGPT? — YouTube
Koala
Koala - это языковая модель в стиле ассистента ChatGPT-like, доработанная на основе LLaMA.
- Блог: Koala: A Dialogue Model for Academic Research — The Berkeley Artificial Intelligence Research Blog
- репозиторий GitHub: EasyLM/koala.md at main · young-geng/EasyLM (github.com)
- Demo: FastChat (lmsys.org)
llama.cpp
Иференс LLaMA - подобных моделей на чистом C/C++ на CPU.
- репозиторий GitHub: ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++ (github.com)
- Поддерживает: LLaMA, Alpaca, and GPT4All, Vicuna
Lit-LLaMA ️
Независимая реализация LLaMA с полностью открытым исходным кодом под лицензией Apache 2.0. Эта реализация основана на nanoGPT.
- репозиторий GitHub: Lightning-AI/lit-llama: Implementation of the LLaMA language model based on nanoGPT. Supports quantization, LoRA fine-tuning, pre-training. Apache 2.0-licensed. (github.com)
Vicuna (FastChat)
Чатбот с открытым исходным кодом, впечатляющий GPT-4 с 90% качеством ChatGPT.
- репозиторий GitHub: lm-sys/FastChat: The release repo for “Vicuna: An Open Chatbot Impressing GPT-4” (github.com)
- Обзор: Vicuna — 90% of ChatGPT quality by using a new dataset? — YouTube
BLOOM (BigScience)
Большая открытая многоязычная языковая модель от сообщества BigScience.
- Hugging Face: bigscience/bloom · Hugging Face
- Hugging Face Demo: Bloom Demo — a Hugging Face Space by huggingface
Вот список форков проекта BLOOM или основанных на нем:
BLOOM-LoRA
Низкоранговая адаптация для различных наборов данных Instruct-Tuning.
- репозиторий GitHub: linhduongtuan/BLOOM-LORA: Due to restriction of LLaMA, we try to reimplement BLOOM-LoRA (much less restricted BLOOM license here https://huggingface.co/spaces/bigscience/license) using Alpaca-LoRA and Alpaca_data_cleaned.json (github.com)
Petals
Генерация текста с использованием 176B-параметров моделей BLOOM или BLOOMZ с возможностью дообучения на ваших задачах.
- репозиторий GitHub: bigscience-workshop/petals: 🌸 Run 100B+ language models at home, BitTorrent-style. Fine-tuning and inference up to 10x faster than offloading (github.com)
Cerebras-GPT (Cerebras)
Семейство открытых, вычислительно эффективных, больших языковых моделей. Cerebras открывает исходный код семи моделей GPT-3 с числом параметров от 111 миллионов до 13 миллиардов. Обученные по архитектуры Chinchilla, эти модели устанавливают новые эталоны точности и эффективности вычислений.
- сайт: Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models — Cerebras
- Hugging Face: cerebras (Cerebras) (huggingface.co)
- Обзор: Checking out the Cerebras-GPT family of models — YouTube
Flamingo (Google/Deepmind)
Решение нескольких задач с помощью одной визуальной языковой модели
Список форков проекта "Flamingo" или работ, основанных на нем:
Flamingo — Pytorch
Реализация Flamingo, state-of-the-art на Pytorch.
- репозиторий GitHub: https://github.com/lucidrains/flamingo-pytorch
OpenFlamingo
Открытая реализация модели Flamingo от DeepMind! В этом репозитории доступна имплементация на PyTorch для обучения и инференса моделей OpenFlamingo. Так же доступна начальная модель OpenFlamingo 9B, обученная на новом датасете Multimodal C4.
- репозиторий GitHub: mlfoundations/open_flamingo: An open-source framework for training large multimodal models (github.com)
FLAN (Google)
Этот репозиторий содержит код для создания коллекций данных для тюнинга. Первая - это оригинальный Flan 2021, документированный в разделе Finetuned Language Models are Zero-Shot Learners, и вторая расширенная верси, Flan Collection, описанная в The Flan Collection: Designing Data and Methods for Effective Instruction Tuning, используемая при создании Flan-T5 и Flan-PaLM.
- репозиторий GitHub: google-research/FLAN (github.com)
Форки, основанный на проектной базе FLAN:
Flan-Alpaca
Обучение на инструкциях от людей и других моделей. Репозиторий содержит расширение наработок Stanford Alpaca, синтетическая настройка инструкций к существующим моделям с настройкой инструкций, таким как Flan-T5.
- репозиторий GitHub: declare-lab/flan-alpaca: This repository contains code for extending the Stanford Alpaca synthetic instruction tuning to existing instruction-tuned models such as Flan-T5. (github.com)
Flan-UL2
Flan-UL2 это модель энкодер-декодер на базе архитектуры T5. Использует ту же конфигурацию, что и UL2 model выпущенный в начале прошлого года. Он был доработан с помощью оперативной настройки "Flan" и сбора наборов данных.
- Hugging Face: google/flan-ul2 · Hugging Face
- Обзор: Trying Out Flan 20B with UL2 — Working in Colab with 8Bit Inference — YouTube
GLM (General Language Model)
GLM - это общая языковая модель, предварительно обученная с авторегрессионной задачей заполнения пробелов, которая может быть настроена на различные задачи понимания и генерации естественного языка.
GLM-130B
GLM-130B открытая, двухязычная (английский и китайский) модель из 130 миллиардов параметров, предобученная с помощью алгоритма General Language Model (GLM). Она построена для инференса 30B параметров на одной A100 (40G * 8) или V100 (32G * 8) видео картах. С помощью INT4 квантизации, системные требрования могут быть понижены до 4 * RTX 3090 (4*24G) практически без деградации в качестве. На 3 июля 2022г., GLM-130B была натренированная на более чем 400 миллиардов токенов (по 200B для английского и китайского).
- репозиторий GitHub: THUDM/GLM-130B: GLM-130B: An Open Bilingual Pre-Trained Model (ICLR 2023) (github.com)
GPT-J
GPT-J открытая ИИ модель (artificial intelligence language model) разработанная сообществом EleutherAI. GPT-J производит результат работы близкий к GPT-3 от OpenAI на различных задачах с нулевым знанием и даже может превзойти его на задачах генерации кода.
- репозиторий GitHub: https://github.com/kingoflolz/mesh-transformer-jax/#gpt-j-6b
- Демка: https://6b.eleuther.ai/
Dolly (Databricks)
Dolly, от компании Databricks, это большая языковая модель, обученная на платформе Databricks Machine Learning Platform, демонстрирует, что модель с открытым исходным кодом двухлетней давности (GPT-J) при дообучении на датасете от Stanford Alpaca, демонстрировать удивительно высокое качество обучения, не характерного для родительской модели, на которой оно основано. Мы считаем этот вывод важным, поскольку он демонстрирует, что возможность создания мощных технологий искусственного интеллекта гораздо более доступна, чем считалось ранее.
- репозиторий GitHub: databrickslabs/dolly: Databricks’ Dolly, a large language model trained on the Databricks Machine Learning Platform (github.com)
- Обзор: Meet Dolly the new Alpaca model — YouTube
GPT-NeoX
Записи в репозитории EleutherAI для обучения расширенных языковых моделей на GPU. Framework основан на Megatron Language Model от NVIDIA и была дополнен методами из DeepSpeed, а также некоторые новые оптимизации.
- репозиторий GitHub: EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the DeepSpeed library. (github.com)
HuggingGPT
HuggingGPT это система совместной работы, которая состоит из LLM как контроллера и множество экспертных моделей работающих прямо с HuggingFace хаба.
- репозиторий GitHub: microsoft/JARVIS: JARVIS, a system to connect LLMs with ML community (github.com)
Polyglot
Большие языковые модели хорошо сбалансированной компетенции в нескольких языках. Были выпущены различные многоязычные модели, такие как mBERT, BLOOM и XGLM. Поэтому кто-то может спросить: "Зачем намсоздавать новые многоязычные модели?". Прежде чем ответить на этот вопрос, мы хотели бы спросить: "Почему люди во всем мире создают моноязычные модели на своем языке, хотя уже существует множество многоязычных моделей?". Мы хотели бы отметить, что одной из наиболее значимых причин является неудовлетворенность неанглоязычной производительностью существующих многоязычных моделей. Поэтому мы хотим создать многоязычные модели с более высокими показателями неанглийского языка. Это причина, по которой нам нужно снова создавать многоязычные модели и почему мы называем их "Polyglot".
- репозиторий GitHub: EleutherAI/polyglot: Polyglot: Large Language Models of Well-balanced Competence in Multi-languages (github.com)
Pythia
Интерпретация авторегрессионных трансформаторов во времени и масштабе
- репозиторий GitHub: EleutherAI/pythia (github.com)
The RWKV Language Model
RWKV: Распараллеливаемые большие языковые модели с производительностью на уровне трансформеров, основанные на архитектуре RNN.
- репозиторий GitHub: BlinkDL/RWKV-LM
- ChatRWKV: with “stream” and “split” strategies and INT8. 3G VRAM is enough to run RWKV 14B :) https://github.com/BlinkDL/ChatRWKV
- демка Hugging Face 14б: HuggingFace Gradio demo (14B ctx8192)
- демка Hugging Face 7б: Raven (7B finetuned on Alpaca) Demo
- RWKV pip package: https://pypi.org/project/rwkv/
- Обзор: Raven — RWKV-7B RNN’s LLM Strikes Back — YouTube
XGLM
Модель XGLM была предложена в Few-shot Learning with Multilingual Language Models.
- репозиторий GitHub: https://github.com/facebookresearch/fairseq/tree/main/examples/xglm
- Hugging Face: https://huggingface.co/docs/transformers/model_doc/xglm
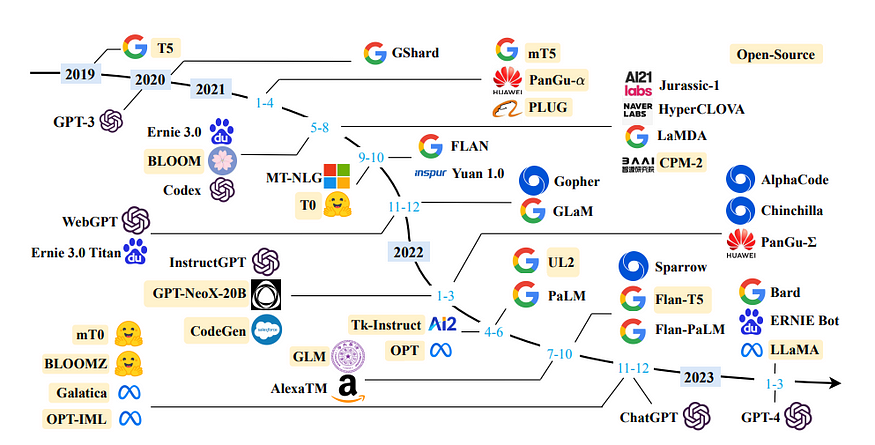
[2303.18223] A Survey of Large Language Models (arxiv.org) — Page 5
- LLMMaps — A Visual Metaphor for Stratified Evaluation of Large Language Models: https://arxiv.org/abs/2304.00457
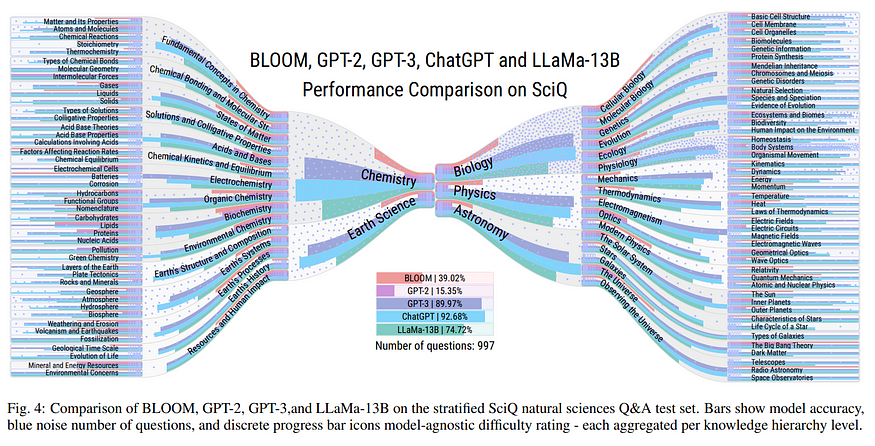
https://arxiv.org/pdf/2304.00457.pdf — Page 7
- PRIMO.ai Large Language Model (LLM): https://primo.ai/index.php?title=Large_Language_Model_(LLM)
- A Survey of Large Language Models: [2303.18223] A Survey of Large Language Models (arxiv.org)