Memorizing Transformers: Как наделить языковую моделью способностью внешней памяти до 260 тыс токенов
Обычно для обучения языковых моделей новым знаниям, необходимо дообучение, что предполагает обновление их весов. Вместо этого мы предлагаем подход, который позволит языковым моделям просто считывать и запоминать новые данные во время инференса, таким образом, получая новые знания в режиме реального времени. В этой работе авторы расширяют возможности языковой модели способностью запоминать внутренние представления прошлых контекстов. Мы демонстрируем, что приблизительный kNN-поиск в недифференцируемой памяти недавних пар (ключ, значение) улучшает языковое моделирование на различных эталонах и задачах, включая общий webtext (C4), математические статьи (arXiv), книги (PG-19), код (Github), а также формальные теоремы (Isabelle). Мы показываем, что производительность неуклонно улучшается при увеличении объема памяти до 262K лексем. На эталонных тестах, включающих код и математику, мы обнаружили, что модель способна использовать вновь определенные функции и теоремы во время тестирования.
Современные языковые модели это комплексные, сложные нейросети. Но у них есть ряд недостатков. Один из главных недостатков — длина контекста (количество токенов, которыми модель способна оперировать при создании новой информации).
В стандартной GPT-4, к примеру, длина контекста — 8.000 токенов, в расширенной — 32.000. Самая мощная на сегодня модель GPT-4 умеет оперировать только 32.000 токенов поданного на вход текста.
Увеличивать контекст модели довольно дорого по времени, количеству параметров и памяти. Поэтому ищутся другие способы. Один из вариантов — вариации "внешней памяти". В эту внешнюю память в каком-то виде складируется информация из входного текста, а модель в процессе работы с помощью некого механизма вытаскивает оттуда релевантные части для текущего шага генерации.
Идея внешней памяти сама по себе не нова. Данный подход применяется в СV, и в NLP развивают много лет со всех сторон. Разработчики из Google придумали новую идею этого механизма, довольно простую и эффекивную.
Вот в чем идея:
Устройство показано на 1 картинке к посту. Берем обычную языковую модель (трансформер). Берем один слой attention внутри этого трансформера (авторы берут слой, близкий к концу сети). К этому слою приделываем хранилище key-value пар, механизм выделения из хранилица нужной инфы и механизм использования этой инфы — еще один attention.
На каждом шаге генерации языковой модели происходит следующее:
- В хранилище добавляются все значения key и value для всех поданых на вход токенов и всех голов attention этого слоя;
- Для значений query всех поданых на вход токенов с помощью KNN ищутся k ближайших key-value пар из хранилища;
- Считается attention между query всех поданых на вход токенов и этими k ближайшими key-value парами. Из k полученных значений attention для каждого токена берется взвешенное среднее — получается одно значение attention на каждый входной токен;
- Считается обычный attention между query, key и value всех поданых на вход токенов;
- Два полученных attention фьюзятся в один также с помощью взвешенного среднего.
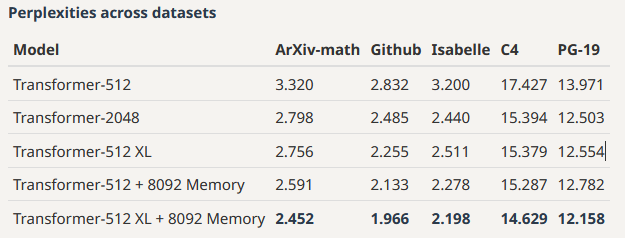
Эксперименты показывают, что такая идея позволяет модели выделять релевантную информацию из памяти, которая была записана туда много-много токенов назад. Авторы тестировали модель на разных датасетах, включая датасет статей из arxiv, кода на GitHub, а также PG-19 — это датасет книг на английском языке, который стал классическим бенчмарком для проверки long-range natural language text modeling.
В общем-то, на всех них perplexity модели с памятью вместимостью 65к токенов выигрывает у модели без памяти (2 картинка к посту). Более того, у авторов получилось, что небольшой трансформер с внешней памятью всего 8к может показывать те же результаты, что большой трансформер без памяти, у которого в 5 раз больше обучаемых параметров.
Важно еще, что эту память можно приделать при дообучении предобученной модели. Дообучать придется не очень много — модель быстро учится использовать механизм памяти и улучшает результат (3 картинка к посту)
Обучение и вывод и состояние внешней памяти.
Внешняя память заполняется парами (ключ, значение), сформированными в процессе обучения.
Вопросы и ответы:
1. Как инициализируется память? Пуста ли она в начале обучения?
Да, когда мы начинаем читать новый документ, память инициализируется как пустая.
2 Какова частота обновления памяти? Делается ли это на каждой итерации, или один раз после нескольких итераций?
Мы обновляем память, как только закончим чтение текущего фрагмента. Таким образом, каждую итерацию.
3 "Если документ очень длинный, старые пары (ключ, значение) будут удалены из памяти, чтобы освободить место для новых". Каков критерий для удаления пар ключ-значение из внешней памяти? Основывается ли он на временных метках итераций или есть какие-то другие метрики, используемые для их удаления?
Мы реализуем скользящий буфер для памяти. Таким образом, самая ранняя память будет отброшена. Улучшение механизма забывания, безусловно, является очень значимым направлением будущих исследований.
4. Замораживается ли память после обучения или она продолжает модифицироваться во время вывода? Если она заморожена, то как вы достигаете следующей цели, упомянутой во введении? "Для этих задач модель должна быть способна работать с большими и постоянно меняющимися хранилищами кода и базами знаний, и должна быть возможность использовать новый добавленный код или факты немедленно без необходимости переобучения или доводки". Если она не заморожена, то как она изменяется во время обучения?
Мы очищаем память, как только закончим чтение документа. Во время вывода, когда мы начинаем читать новый документ, мы снова начинаем с пустой памяти и продолжаем добавлять в нее новые ключи/значения. Это одинаково как для обучения, так и для вывода.
5. Как вычисляются расстояния для kNN. Вычисляется ли оно только между ключевыми векторами или между конкатенацией ключевых векторов и векторов значений? Является ли расстояние L2 расстоянием?
Мы вычисляем показатели внимания между запросами и ключами с помощью точечного произведения и берем top-k.
6. В чем разница между 'Retrieved Context' и 'Retrieved Token'?
Retrieved Context - это просто окружающий контекст (~10 токенов) Retrieved Token. Retrieved Token - это token, которая действительно была извлечена (как одна из топ-к).
Сcылки:
📄 Статья (https://arxiv.org/pdf/2203.08913.pdf)
🛠 Код на GitHub (https://github.com/lucidrains/memorizing-transformers-pytorch) (неофициальный)
При подготовке статьи использовался материал из блога https://t.me/dl_stories.