MiniGPT-4, ты что за зверь такой?

Не проходит и недели, чтобы что-то новое и очень крутое в области LLM не появилось в сети. На этот раз отличились сотрудники из Научно-технологического университета имени короля Абдаллы (технический исследовательский университет в Саудовской Аравии). Они предложили способ наделения языковой модели функцией мультимодальности. Их ресерч называется "Улучшение понимания языка зрения с помощью усовершенствованных больших языковых моделей" (Enhancing Vision-language Understanding with Advanced Large Language Models).
Недавняя демонстрация возможностей GPT-4 продемонстрировала экстраординарные мультимодальные способности, такие как прямое создание веб-сайтов из рукописного текста и определение юмористических элементов в изображениях. Такие функции на таком уровне ранее не встречались в языковых моделях и моделях визуального восприятия.
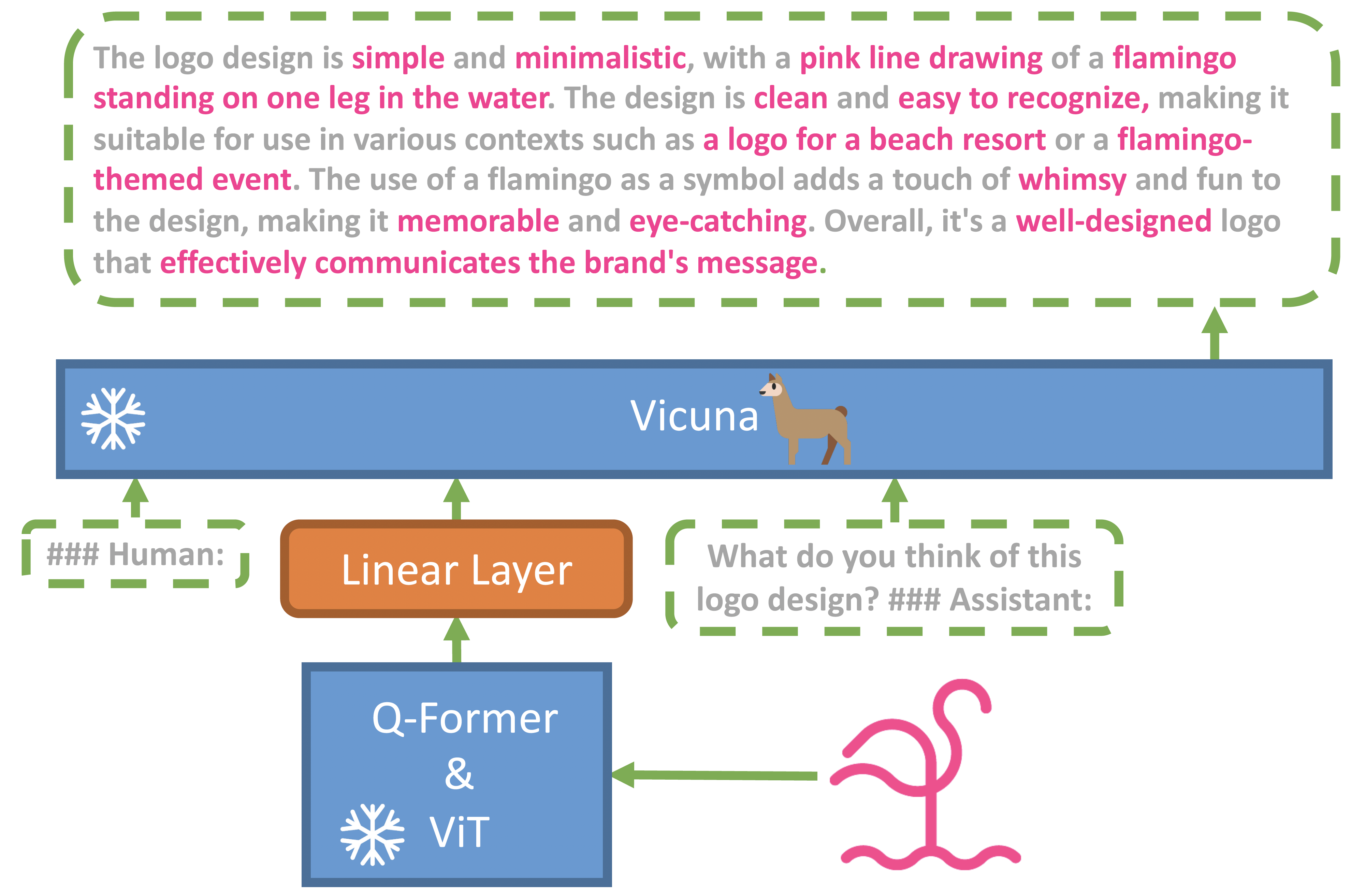
По мнению авторов работы, основная причина расширенных возможностей GPT-4 по мультимодальной генерации заключается в использовании более совершенной большой языковой модели (LLM). Для изучения этого феномена они выкатили MiniGPT-4, модель, которая выравнивает замороженный визуальный энкодер с замороженной LLM (aligns a frozen visual encoder with a frozen LLM), Vicuna, используя только один проекционный слой.
Технически, авторы объединили ужа с ежом языковую и модель визуального восприятия, и получили упрощённый прототип мультимодального GPT-4. Они взяли ViT-L+Q-former из BLIP2 и объединили его с языковой моделью Vicuna-13B, и обучили только линейный слой на определённых наборах данных пар изображение-текст. MiniGPT-4 требует только обучения линейного слоя для выравнивания визуальных характеристик с моделью Vicuna.
И результаты восхитительны! miniGPT-4 обошла оригинальные модели Openflamingo и BLIP2. Самое интересное, что данная реализация мультимодальной модели появилася раньше, чем OpenAI успели публично зарелизить такую фичу у GPT-4. Настоящая победа для ИИ с открытым исходным кодом.
Обучение:
Обучение MiniGPT-4 происходило в два этапа. Первый, этап предварительной подготовки, проводился на ~5 миллионах пар изображение-текст в течении 10 часов с использованием 4xA100. После первого этапа Vicuna стала способна понимать изображение, при этом способность Vicuna генерировать текст сильно просела.
Для решения этой проблемы, авторы попробовали создавать высококачественные пар изображение-текст с помощью самой модели и ChatGPT. Так появился небольшой (всего 3500 пар), но высококачественный набор данных.
На втором этапе модель дообучилась на полученным в результате предыдущего шага наборе данных в виде диалоговых инструкций. В результате значительно улучшилось качество генерации ответов. К удивлению авторов, этот этап является вычислительно эффективным и занимает всего около 7 минут на одном A100. В MiniGPT-4 реализовано множество новых способностей "языка зрения", (emerging vision-language) аналогичных тем, которые были продемонстрированы в GPT-4.
Результаты работы показывают, что MiniGPT-4 обладает многими возможностями, аналогичными GPT-4, такими как генерация подробных описаний изображений и создание веб-сайтов из рукописных черновиков. Кроме того у MiniGPT-4 появились и другие новые способности, включая написание историй и стихов, вдохновленных заданными изображениями, предоставление решений проблем, показанных на изображениях, обучение пользователей приготовлению пищи на основе фотографий блюд и т.д.
В результате эксперимента авторы обнаружили, что предварительное обучение только на необработанных парах "изображение-текст" может привести к неестественным результатам, лишенным связности, включая повторы и обрывочные предложения. Чтобы решить эту проблему, на втором этапе авторы собрали высококачественный, хорошо согласованный набор данных, чтобы доработать модель с помощью разговорных инструкций.
Этот шаг оказался решающим для повышения точности генерации модели и общего удобства использования. Примечательно, что модель очень эффективна с вычислительной точки зрения, поскольку у неё обучен только проекционный слой, используя около 5 миллионов выровненных пар изображение-текст.


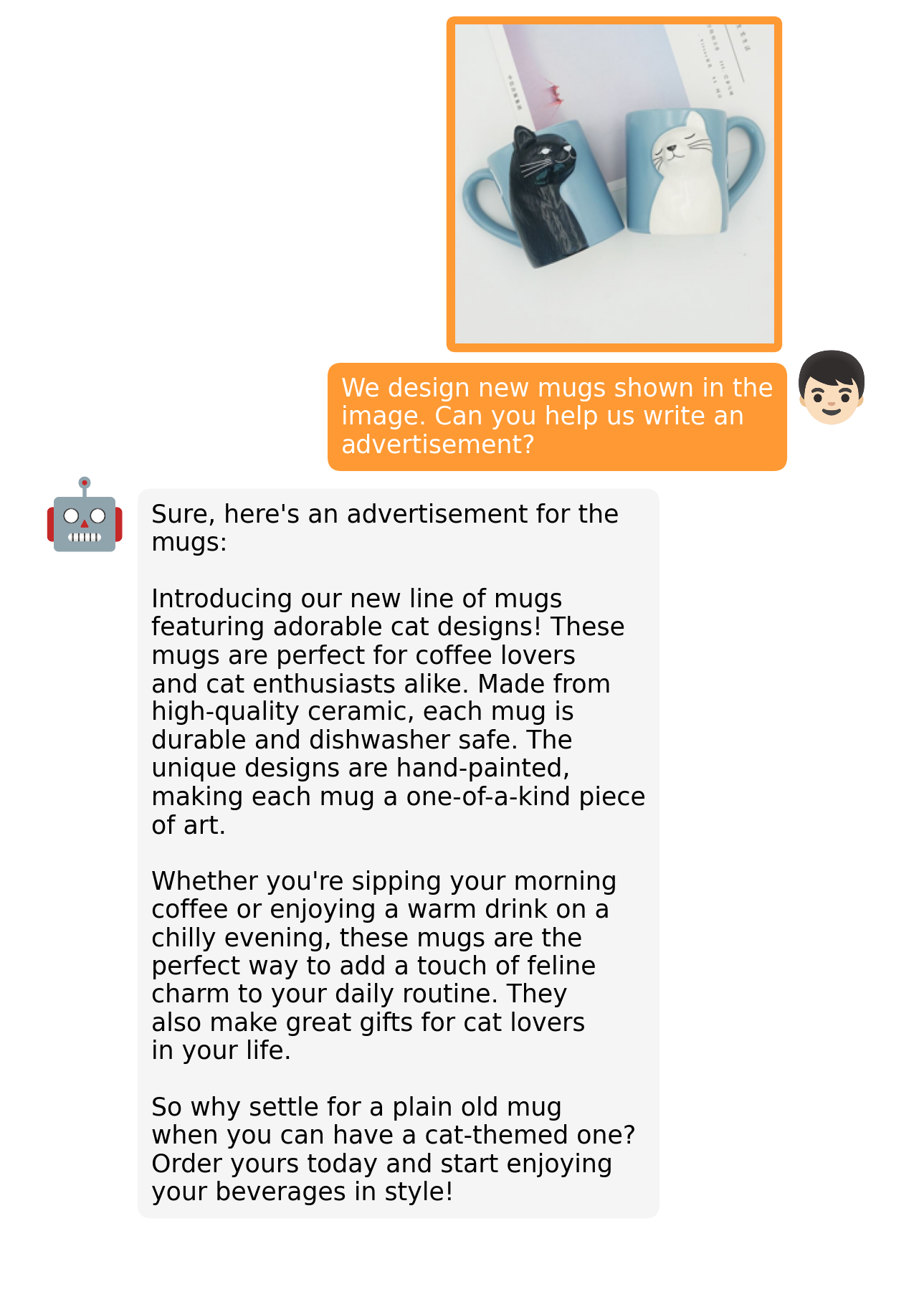

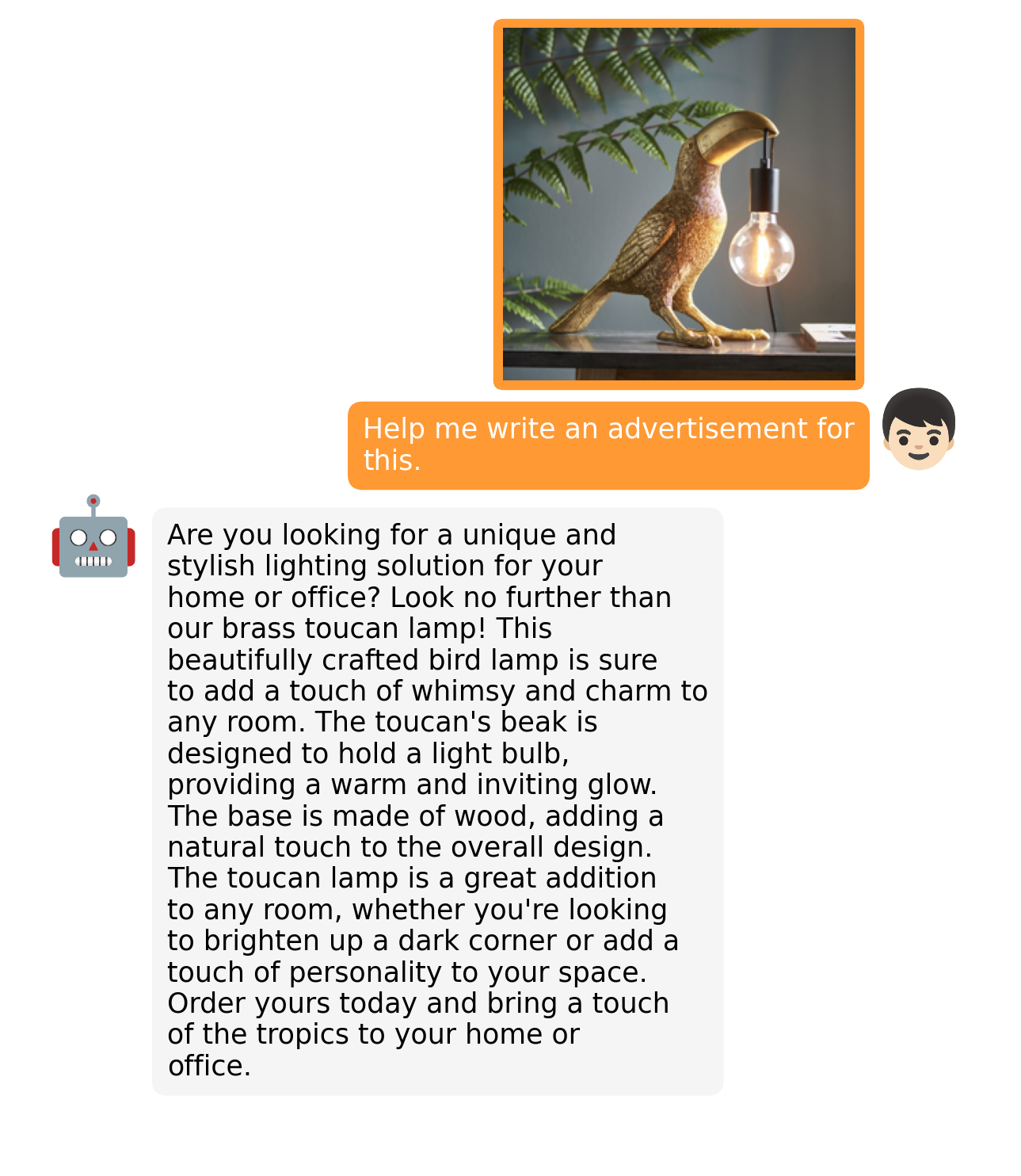
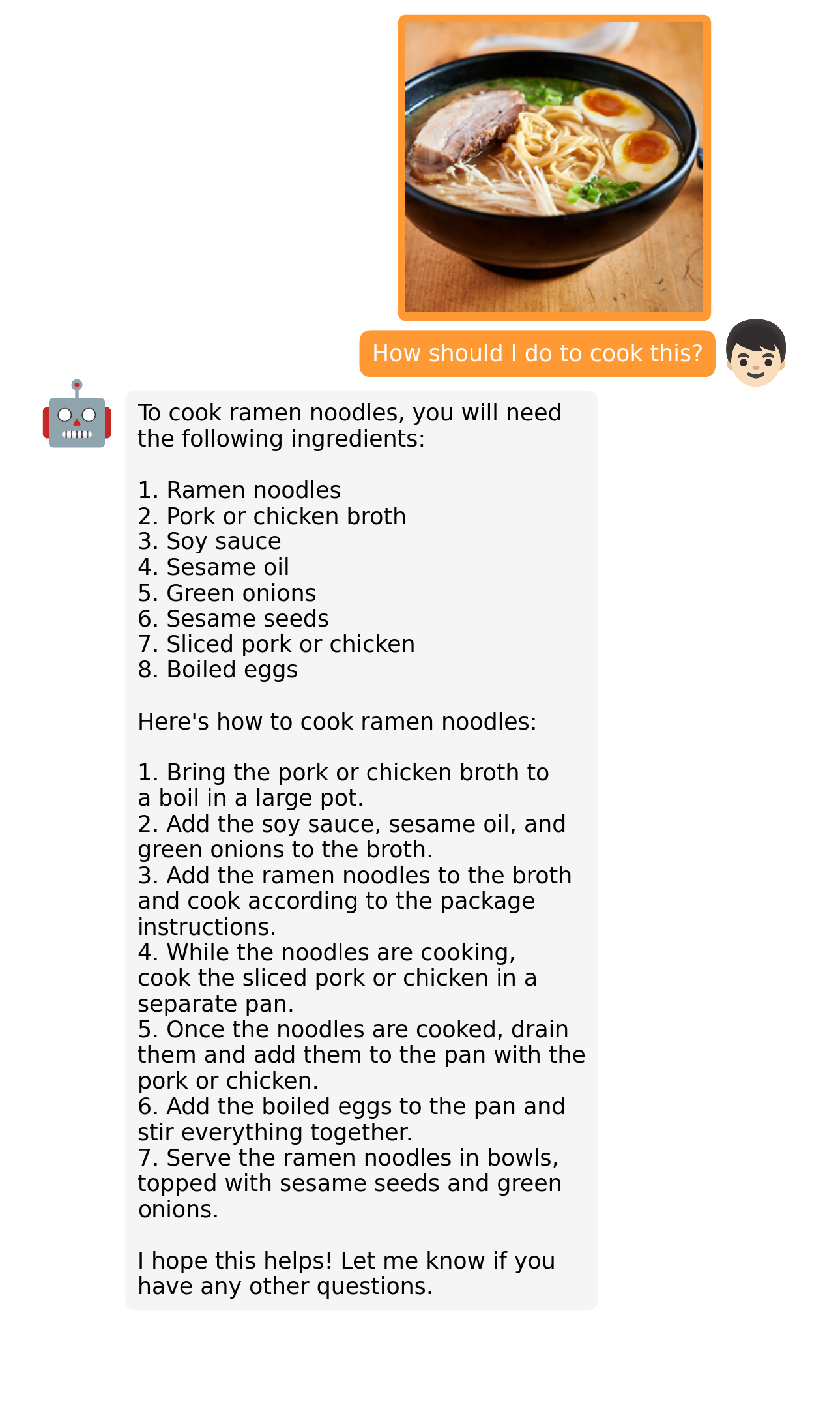
Больше примеров тут.
Код поднятия дискорд бота с miniGPT-4 yf
Код для обучения: https://github.com/Vision-CAIR/MiniGPT-4
Датасет: https://github.com/Vision-CAIR/MiniGPT-4/blob/main/dataset/README_2_STAGE.md
Веса претрейна: https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view
Исследование: https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
Демки: Link1 Link2 Link3 Link4 Link5 Link6 Link7
Лицензия: BSD-3.
Мысли:
Будущее языковых моделей однозначно за мультимодальностью, которая уже сейчас наделяет LLMки новыми способностями. Они учатся приобретать знания, не ограничиваясь лишь текстовыми описаниями. Дальше будет интереснее - передача моделям голоса, звуков, музыки и видео ;)
Уже представляю себе кучу пул-реквестов в репозитории llama.cpp, с запросом расширить поддержку архитектуры для miniGPT-4 и передачи еще одним параметром изображения :)