Список открытых и дообученных больших языковых моделей (LLM)
Mistral.ai представили Mistral 7B. Эта модель превосходит Llama 2 13B, имеет длинное контекстное окно, и запускается на CPU. и… Stability AI представили открытый StableLM-3B-4E1T.
Hugging Face открытый лидерборд:
LLM Leaderboard
Очки у моделей постоянно обновляютяс.
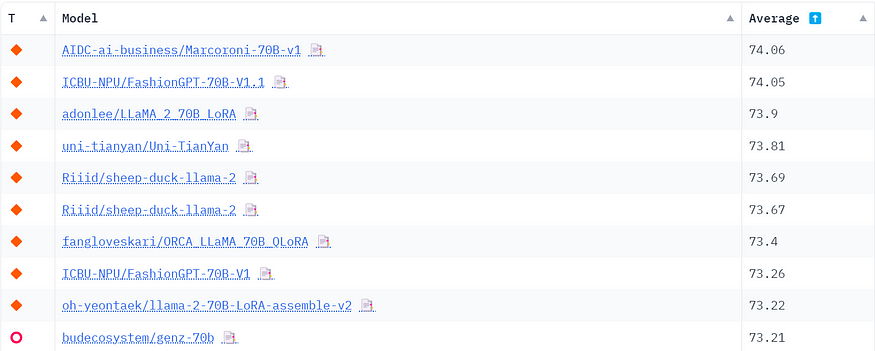
Это неполный список открытых языковых моделей (Large Language Models, LLM), запускающихся на вашем локальном железе, и попытка сохранить этот список, поскольку ежедневно появляются сотни новых моделей. Тут далеко не все новые модели, поскольку можно буквально бесплатно создать эти модели через Google Colab.
Список представляет собой незавершенную работу, в которой модели по предварительно обученным LLM, которые подразделяются на список проектов, являющихся доработанными LLM-версиями этих предварительно обученных LLM.
Далее следует перечисление сайтов, на которых организации и/или частные лица публикуют дообученные LLM. Они обозначены как Person Name/Organization Name's Hugging Face website. Например, Том Джоббинс (Tom Jobbins, TheBloke) разместил на своем сайте более 1700 точно настроенных LLM.
- 03/2023: Added HuggingGPT | Vicuna/FastChat
- 04/2023 Fine-Tuned LLMs: Baize | Koala | Segment Anything | Galpaca | GPT-J-6B instruction-tuned on Alpaca-GPT4 | GPTQ-for-LLaMA | Dolly 2.0 | StackLLaMA | GPT4All-J | Palmyra Base 5B | Camel 🐪 5B | StableLM | h2oGPT | OpenAssistant Models | StableVicuna | FastChat-T5 | couchpotato888 | GPT4-x-Alpaca | LLaMA Adapter V2 | WizardLM
- 04/2023 Others: A Survey of Large Language Models | LLMMaps — A Visual Metaphor for Stratified Evaluation of Large Language Models | A brief history of LLaMA models | List of all Foundation Models
- 05/2023 Pre-Trained LLMs: OpenLLaMA | BigCode StarCoder (Hugging Face + ServiceNow) | Replit-Code (Replit) | Mosaic ML’s MPT-7B | Together’s RedPajama-INCITE 3B and 7B | TII’s Falcon LLM
- 05/2023 Fine-Tuned LLMs: Pygmalion-7b | Nvidia GPT-2B-001 | crumb’s Hugging Face website | Teknium’s Hugging Face website | Knut Jägersberg’s Hugging Face website | gpt4-x-vicuna-13b | LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions | Vigogne | Chinese-LLaMA-Alpaca | OpenBuddy — Open Multilingual Chatbot for Everyone | | PaLM (Concept of Mind) | digitous Hugging Face website | Hugging Face’s Open LLM Leaderboard | A’eala’s Hugging Face website | chavinlo’s Hugging Face website | eachadea’s Hugging Face website | chainyo’s Hugging Face website | KoboldAI’s Hugging Face website | Baize V2 | Gorilla (POET?) | QLoRA | ausboss’ Hugging Face website | Metal (MetaIX)’s Hugging Face website
- 05/2023 Others: SemiAnalysis article by Luke Sernau (a senior software engineer at Google) | Chatbot Arena | Ahead of AI #8: The Latest Open Source LLMs and Datasets (Resources section)
- 06/2023 Pre-Trained LLMs: InternLM | OpenLLaMA 13B | Baichuan Intelligent Technology’s baichuan | BAAI’s Aquilla | Mosaic ML’s MPT-30B | Tsinghua University’s ChatGLM2–6B | Salesforce XGen |
- 06/2023 Fine-Tuned LLMs: CalderaAI/30B-Lazarus | elinas’ Hugging Face website | Tim Dettmers’ Hugging Face website | Tiger Research’s Hugging Face website | Eric Hartford’s Hugging Face website | pinkmanlove’s Hugging Face website | Huggy Llama’s Hugging Face website | AllenAI’s Tulu 65B | CarperAI’s Hugging Face website | Eugene Pentland’s Hugging Face website | Concept of Mind’s Hugging Face website | ClimateBert’s Hugging Face website | LLMs’ Hugging Face website | Jon Durbin’s Hugging Face website | Benjamin Anderson’s Hugging Face website | Georgia Tech Research Institute’s Hugging Face website | OptimalScale’s Hugging Face website | FlashVenom’s Hugging Face website | Michael’s Hugging Face website | Pankaj Mathur’s Hugging Face website | Manuel Romero’s Hugging Face website | OpenFlamingo V2 | Francisco Jaque’s Hugging Face website
- 06/2023 Others: AlpacaEval Leaderboard
- 07/2023 Pre-Trained LLMs: Salesforce CodeGen 2.5 | InternLM-7B | OpenBMB CPM-Bee | Baichuan Intelligent Technology’s baichuan-13B | Writer’s Palmyra-20b | Tiger Research’s TigerBot | EleutherAI’s Pythia | EleutherAI’s GPT-Neo | Machine Translation Team at Alibaba DAMO Academy’s PolyLM | jina.ai’s jina-embedding-s-en-v1 | Llama 2
- 07/2023 Fine-Tuned LLMs: Sahil Chaudhary’s Hugging Face website | LongLLaMA | theblackcat102's Hugging Face website | Tencent Music Entertainment Lyra Lab’s Hugging Face website | LINCE-ZERO (Llm for Instructions from Natural Corpus en Español) | Writer’s InstructPalmyra-20b | H2O.ai’s h2ogpt-research-oasst1-llama-65b | RWKV-4-World | seonghyeonye’s FLIPPED-11B | psmathur’s Orca-Mini — V2–13B | OpenOrca-Preview1–13B | LMSYS’s Vicuna-7B v.1.1 | Upstage.ai’s upstage/llama-30b-instruct-2048 | lilloukas/GPlatty-30B | arielnlee/SuperPlatty-30B | Stability AI’s FreeWilly2 | jondurbin/airoboros-l2–70b-gpt4–1.4.1 (Jon Durbin’s Hugging Face website) | TheBloke/llama-2–70b-Guanaco-QLoRA-fp16 (The Bloke’s Hugging Face website) | TheBloke/gpt4-alpaca-lora_mlp-65B-HF (The Bloke’s Hugging Face website) | jondurbin/airoboros-65b-gpt4–1.2 (Jon Durbin’s Hugging Face website) | stabilityai/StableBeluga2 (replaces stabilityai/FreeWilly2) | stabilityai/StableBeluga1-Delta | TheBloke/gpt4-alpaca-lora_mlp-65B-HF (The Bloke’s Hugging Face website) | jondurbin/airoboros-65b-gpt4–1.2 (Jon Durbin’s Hugging Face website) | TheBloke/guanaco-65B-HF (The Bloke’s Hugging Face website) | dfurman/llama-2–70b-dolphin-peft (Daniel Furman’s Hugging Face website) | LLongMA-2 16k (Concept of Mind’ Hugging Face website) | TogetherAI’s LLaMA-2–7B-32K | upstage/Llama-2–70b-instruct-1024 | upstage/Llama-2–70b-instruct | augtoma/qCammel-70-x (see Augustin Toma’s Hugging Face website)
- 07/2023 Others: LLMSurvey | Open LLM-Perf Leaderboard | MT-Bench Leaderboard | A Survey on Multimodal Large Language Models
- 08/2023: Pre-Trained LLMs: Meta’s Shepherd | G42’s Jais | TII’s Falcon 180B | Adept Persimmon-8B | microsoft/phi-1_5
- 08/2023 Fine-Tuned LLMs: garage-bAInd/Platypus2–70B-instruct (see garage-bAlnd’s Hugging Face website) | deepnight-research/llama-2–70B-inst (see Deepnight’s Hugging Face website) | psmathur/model_007 (see Pankaj Mathur’s Hugging Face website) | quantumaikr/llama-2–70b-fb16-guanaco-1k (see quantumai.kr’s Hugging Face website) | dfurman/llama-2–70b-dolphin-peft (see Daniel Furman’s Hugging Face website) | garage-bAInd/Dolphin-Platypus2–70B (see garage-bAlnd’s Hugging Face website) | WizardLM/WizardLM-70B-V1.0 (see WizardLM’s Hugging Face website) | Giraffe | NousResearch/Nous-Hermes-Llama2–70b | ehartford/Samantha-1.11–70b | budecosystem/genz-70b | OpenAssistant/llama2–70b-oasst-sft-v10 | ehartford/Samantha-1.11-CodeLlama-34b | pharaouk/unnatural_codellama_34B | Phind/Phind-CodeLlama-34B-v1 | QwenLM/Qwen-VL | NousResearch/Nous-Puffin-70B | Code Llama | jondurbin/airoboros | NousResearch/Nous-Hermes-Llama2–70b | jondurbin/airoboros-l2–70b-2.1 | fangloveskari/ORCA_LLaMA_70B_QLoRA | fangloveskari/Platypus_QLoRA_LLaMA_70b | uni-tianyan/Uni-TianYan | garage-bAInd/Platypus2–70B-instruct | yeontaek/llama-2–70B-ensemble-v5 | Riiid/sheep-duck-llama-2 · Hugging Face | AIDC-ai-business/Marcoroni-70B
- 09/2023: Pre-Trained LLMs: Cerebras’ BTLM-3B-8K | Alibaba Cloud’s Qwen-14B | Abacus.ai’ s Giraffe 70B | Mistral.ai’s Mistral 7B | Shanghai Artificial Intelligence Laboratory’s internlm/internlm-chat-20b | smallcloudai/Refact-1_6B-fim | OpenBA | TinyLlama | ModuleFormer | Deci/DeciLM-6b | MAmmoTH | stabilityai/stablelm-3b-4e1t
- 09/2023: Fine-Tuned LLMs: NousResearch/Nous-Capybara-7B-GGUF | Alpha-VLLM/WeMix-LLaMA2–7B | Alpha-VLLM/WeMix-LLaMA2–70B | Duxiaoman-DI/XuanYuan-70B | meta-math/MetaMath-7B-V1.0 | | Yukang/Llama-2–13b-chat-longlora-32k-sft | Yukang/Llama-2–70b-chat-longlora-32k-sft | syzymon/long_llama_code_7b | GAIR/GAIRMath-Abel-70b | Xwin-LM/Xwin-LM-70B-V0.1 | glaiveai/glaive-coder-7b | Riiid/sheep-duck-llama-2 | teknium/OpenHermes-13B | Nexusflow/NexusRaven-13B | migtissera/Synthia-7B-v1.3 | LeoLM/leo-hessianai-13b | migtissera/Synthia-13B-v1.2
LLaMA and Llama2 (Meta)
Meta release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closedsource models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
- Paper: Llama 2: Open Foundation and Fine-Tuned Chat Models | Meta AI Research
- Blog: Llama 2 — Meta AI
- Hugging Face: Models — Hugging Face
Alpaca.cpp
Run a fast ChatGPT-like model locally on your device. The screencast below is not sped up and running on an M2 Macbook Air with 4GB of weights.
Alpaca-LoRA
This repository contains code for reproducing the Stanford Alpaca results using low-rank adaptation (LoRA). We provide an Instruct model of similar quality totext-davinci-003that can run on a Raspberry Pi (for research), and the code is easily extended to the13b,30b, and65bmodels.
- GitHub: tloen/alpaca-lora: Instruct-tune LLaMA on consumer hardware (github.com)
- Demo: Alpaca-LoRA — a Hugging Face Space by tloen
Chinese-LLaMA-Alpaca
In order to promote the open research of large models in the Chinese NLP community, this project open sourced the Chinese LLaMA model and the Alpaca large model with fine-tuned instructions.
StableBeluga2
Stable Beluga 2 is a Llama2 70B model finetuned on an Orca style Dataset- Hugging Face: https://huggingface.co/stabilityai/StableBeluga2
- Hugging Face: https://huggingface.co/stabilityai/StableBeluga-7B
- Hugging Face: https://huggingface.co/stabilityai/StableBeluga-13B
Giraffe
Giraffe is a new family of models that are finetuned from base LLaMA and LLaMA2 that we release. We include a 4k Giraffe and 16k Giraffe finetuned from LLaMA, and a 32k Giraffe finetuned from LLaMA2 and release their weights on HuggingFace. We also release our training code, evaluation datasets, and evaluation scripts to the research community.
Gorilla (POET?)
POET enables the training of state-of-the-art memory-hungry ML models on smartphones and other edge devices. POET (Private Optimal Energy Training) exploits the twin techniques of integrated tensor rematerialization, and paging-in/out of secondary storage (as detailed in our paper at ICML 2022) to optimize models for training with limited memory. POET's Mixed Integer Linear Formulation (MILP) ensures the solutions are provably optimal!- Website: Gorilla (berkeley.edu)
- GitHub: ShishirPatil/poet: ML model training for edge devices (github.com)
GPT4All
Demo, data and code to train an assistant-style large language model with ~800k GPT-3.5-Turbo Generations based on LLaMa.
- GitHub: nomic-ai/gpt4all: gpt4all: a chatbot trained on a massive collection of clean assistant data including code, stories and dialogue (github.com)
- GitHub: nomic-ai/pyllamacpp: Official supported Python bindings for llama.cpp + gpt4all (github.com)
- Review: Is GPT4All your new personal ChatGPT? — YouTube
Koala
Koala is a language model fine-tuned on top of LLaMA. Check out the blogpost! This documentation will describe the process of downloading, recovering the Koala model weights, and running the Koala chatbot locally.
- Blog: Koala: A Dialogue Model for Academic Research — The Berkeley Artificial Intelligence Research Blog
- GitHub: EasyLM/koala.md at main · young-geng/EasyLM (github.com)
- Demo: FastChat (lmsys.org)
- Review: Investigating Koala a ChatGPT style Dialogue Model — YouTube
- Review: Running Koala for free in Colab. Your own personal ChatGPT? — YouTube
llama.cpp
Inference of LLaMA model in pure C/C++
- GitHub: ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++ (github.com)
- Supports three models: LLaMA, Alpaca, and GPT4All
LLaMA-Adapter V2
Official implementation of ‘LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention’ and ‘LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model’.
- GitHub: ZrrSkywalker/LLaMA-Adapter: Fine-tuning LLaMA to follow Instructions within 1 Hour and 1.2M Parameters (github.com)
LLaMA-2–7B-32K (TogetherAI)
A 32K context model built using Position Interpolation and Together AI’s data recipe and system optimizations, including FlashAttention-2. Fine-tune the model for targeted, long-context tasks — such as multi-document understanding, summarization, and QA — and run inference and fine-tune on 32K context with up to 3x speedup.
Lit-LLaMA ️
Independent implementation of LLaMA that is fully open source under the Apache 2.0 license. This implementation builds on nanoGPT.
- GitHub: Lightning-AI/lit-llama: Implementation of the LLaMA language model based on nanoGPT. Supports quantization, LoRA fine-tuning, pre-training. Apache 2.0-licensed. (github.com)
LongLLaMA
LongLLaMA, a large language model capable of handling long contexts of 256k tokens or even more.
- Hugging Face: syzymon/long_llama_3b · Hugging Face
- GitHub: CStanKonrad/long_llama: LongLLaMA is a large language model capable of handling long contexts. It is based on OpenLLaMA and fine-tuned with the Focused Transformer (FoT) method. (github.com)
- Colab: long_llama_colab.ipynb — Colaboratory (google.com)
OpenAlpaca
This is the repo for the OpenAlpaca project, which aims to build and share an instruction-following model based on OpenLLaMA. We note that, following OpenLLaMA, OpenAlpaca is permissively licensed under the Apache 2.0 license. This repo contains- The data used for fine-tuning the model.
- The code for fine-tuning the model.
- The weights for the fine-tuned model.
- The example usage of OpenAlpaca.
- GitHub: yxuansu/OpenAlpaca: OpenAlpaca: A Fully Open-Source Instruction-Following Model Based On OpenLLaMA (github.com)
OpenBuddy — Open Multilingual Chatbot for Everyone
OpenBuddy is a powerful open-source multilingual chatbot model aimed at global users, emphasizing conversational AI and seamless multilingual support for English, Chinese, and other languages. Built upon Facebook’s LLAMA model, OpenBuddy is fine-tuned to include an extended vocabulary, additional common characters, and enhanced token embeddings. By leveraging these improvements and multi-turn dialogue datasets, OpenBuddy offers a robust model capable of answering questions and performing translation tasks across various languages.
Pygmalion-7b
Pygmalion 7B is a dialogue model based on Meta’s LLaMA-7B. This is version 1. It has been fine-tuned using a subset of the data from Pygmalion-6B-v8-pt4, for those of you familiar with the project.
- Hugging Face: https://huggingface.co/PygmalionAI/pygmalion-7b
QLoRA
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters (LoRA).
GitHub: artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs (github.com)
StableVicuna
We are proud to present StableVicuna, the first large-scale open source chatbot trained via reinforced learning from human feedback (RHLF). StableVicuna is a further instruction fine tuned and RLHF trained version of Vicuna v0 13b, which is an instruction fine tuned LLaMA 13b model. For the interested reader, you can find more about Vicuna here.
- Website: Stability AI releases StableVicuna, the AI World’s First Open Source RLHF LLM Chatbot — Stability AI
- Hugging Face: StableVicuna — a Hugging Face Space by CarperAI
- Review: StableVicuna: The New King of Open ChatGPTs? — YouTube
StackLLaMA
A LlaMa model trained on answers and questions on Stack Exchange with RLHF through a combination of: Supervised Fine-tuning (SFT), Reward / preference modeling (RM), and Reinforcement Learning from Human Feedback (RLHF)
Website: https://huggingface.co/blog/stackllama
Tulu 65B (AllenAI)
This is the repository for the paper How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources .We explore instruction-tuning popular base models on publicly available datasets.
- GitHub: allenai/open-instruct (github.com)
- Hugging Face: allenai/tulu-65b · Hugging Face
Vicuna (FastChat)
An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality.
- GitHub: lm-sys/FastChat: The release repo for “Vicuna: An Open Chatbot Impressing GPT-4” (github.com)
- Review: Vicuna — 90% of ChatGPT quality by using a new dataset? — YouTube
Vigogne
This repository contains code for reproducing the Stanford Alpaca in French 🇫🇷 using low-rank adaptation (LoRA) provided by 🤗 Hugging Face’s PEFT library. In addition to the LoRA technique, we also use LLM.int8() provided by bitsandbytes to quantize pretrained language models (PLMs) to int8. Combining these two techniques allows us to fine-tune PLMs on a single consumer GPU such as RTX 4090.
GitHub: https://github.com/bofenghuang/vigogne
WizardLM
An Instruction-following LLM Using Evol-Instruct. Empowering Large Pre-Trained Language Models to Follow Complex Instructions
- GitHub: nlpxucan/WizardLM: WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions (github.com)
- Review: WizardLM: Evolving Instruction Datasets to Create a Better Model — YouTube
BAAI’s Aquila
The Aquila language model inherits the architectural design advantages of GPT-3 and LLaMA, replacing a batch of more efficient underlying operator implementations and redesigning the tokenizer for Chinese-English bilingual support.
- GitHub: FlagAI/examples/Aquila at master · FlagAI-Open/FlagAI · GitHub
- Hugging Face: BAAI (Beijing Academy of Artificial Intelligence) (huggingface.co)
Baichuan Intelligent Technology’s baichuan
baichuan-7B is an open-source large-scale pre-trained model developed by Baichuan Intelligent Technology. Based on the Transformer architecture, it is a model with 7 billion parameters trained on approximately 1.2 trillion tokens. It supports both Chinese and English, with a context window length of 4096. It achieves the best performance of its size on standard Chinese and English authoritative benchmarks (C-EVAL/MMLU).
- GitHub: baichuan-inc/baichuan-7B: A large-scale 7B pretraining language model developed by BaiChuan-Inc. (github.com)
- Hugging Face: baichuan-inc/baichuan-7B · Hugging Face
BLOOM (BigScience)
BigScience Large Open-science Open-access Multilingual Language Model.
- Hugging Face: bigscience/bloom · Hugging Face
- Hugging Face Demo: Bloom Demo — a Hugging Face Space by huggingface
Here is a list of reproductions of or based on the BLOOM project:
BLOOM-LoRA
Low-Rank adaptation for various Instruct-Tuning datasets.
- GitHub: linhduongtuan/BLOOM-LORA: Due to restriction of LLaMA, we try to reimplement BLOOM-LoRA (much less restricted BLOOM license here https://huggingface.co/spaces/bigscience/license) using Alpaca-LoRA and Alpaca_data_cleaned.json (github.com)
Petals
Generate text using distributed 176B-parameter BLOOM or BLOOMZ and fine-tune them for your own tasks.
- GitHub: bigscience-workshop/petals: 🌸 Run 100B+ language models at home, BitTorrent-style. Fine-tuning and inference up to 10x faster than offloading (github.com)
Cerebras-GPT (Cerebras)
A Family of Open, Compute-efficient, Large Language Models. Cerebras open sources seven GPT-3 models from 111 million to 13 billion parameters. Trained using the Chinchilla formula, these models set new benchmarks for accuracy and compute efficiency.
- Website: Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models — Cerebras
- Hugging Face: cerebras (Cerebras) (huggingface.co)
- Review: Checking out the Cerebras-GPT family of models — YouTube
CodeGen (Salesforce)
The family of Salesforce CodeGen models is growing with CodeGen2.5 — a small, but mighty model! While there has been a recent trend of large language models (LLM) of increasing size, we show that a small model can obtain surprisingly good performance, when being trained well.
- Website: CodeGen2.5: Small, but mighty (salesforceairesearch.com)
- GitHub: salesforce/CodeGen: CodeGen is an open-source model for program synthesis. Trained on TPU-v4. Competitive with OpenAI Codex. (github.com)
- Hugging Face: Salesforce/codegen25–7b-multi · Hugging Face
CPM-Bee (OpenBMB)
CPM-Bee is a fully open-source, commercially-usable Chinese-English bilingual base model with a capacity of ten billion parameters. It is the second milestone achieved through the training process of CPM-Live. Utilizing the Transformer auto-regressive architecture, CPM-Bee has been pre-trained on an extensive corpus of trillion-scale tokens, thereby possessing remarkable foundational capabilities.
- GitHub: CPM-Bee/README_en.md at main · OpenBMB/CPM-Bee · GitHub
- Hugging Face: openbmb (OpenBMB) (huggingface.co)
- Website: OpenBMB — 让大模型飞入千家万户
Falcon LLM
Falcon LLM is TII’s flagship series of large language models, built from scratch using a custom data pipeline and distributed training library.
- Website: tiiuae (Technology Innovation Institute) (huggingface.co)
- Hugging Face: https://huggingface.co/blog/falcon-180b
- Hugging Face: tiiuae/falcon-40b-instruct · Hugging Face
- Hugging Face: tiiuae/falcon-7b-instruct · Hugging Face
- Review: Falcon Soars to the Top — The NEW 40B LLM Rises above the rest. — YouTube
Flamingo (Google/Deepmind)
Tackling multiple tasks with a single visual language model
Here is a list of reproductions of or based on the Flamingo project:
Flamingo — Pytorch
Implementation of Flamingo, state-of-the-art few-shot visual question answering attention net, in Pytorch. It will include the perceiver resampler (including the scheme where the learned queries contributes keys / values to be attended to, in addition to media embeddings), the specialized masked cross attention blocks, and finally the tanh gating at the ends of the cross attention + corresponding feedforward blocks.
OpenFlamingo
Welcome to our open source version of DeepMind’s Flamingo model! In this repository, we provide a PyTorch implementation for training and evaluating OpenFlamingo models. We also provide an initial OpenFlamingo 9B model trained on a new Multimodal C4 dataset (coming soon). Please refer to our blog post for more details.
- GitHub: mlfoundations/open_flamingo: An open-source framework for training large multimodal models (github.com)
FLAN (Google)
This repository contains code to generate instruction tuning dataset collections. The first is the original Flan 2021, documented in Finetuned Language Models are Zero-Shot Learners, and the second is the expanded version, called the Flan Collection, described in The Flan Collection: Designing Data and Methods for Effective Instruction Tuning and used to produce Flan-T5 and Flan-PaLM.
Here is a list of reproductions of or based on the FLAN project:
FastChat-T5
We are excited to release FastChat-T5: our compact and commercial-friendly chatbot! that is Fine-tuned from Flan-T5, ready for commercial usage! and Outperforms Dolly-V2 with 4x fewer parameters.
- GitHub: lm-sys/FastChat: The release repo for “Vicuna: An Open Chatbot Impressing GPT-4” (github.com)
- Hugging Face: https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/huggingface_api.py
Flan-Alpaca
Instruction Tuning from Humans and Machines. This repository contains code for extending the Stanford Alpaca synthetic instruction tuning to existing instruction-tuned models such as Flan-T5. The pretrained models and demos are available on HuggingFace
- GitHub: declare-lab/flan-alpaca: This repository contains code for extending the Stanford Alpaca synthetic instruction tuning to existing instruction-tuned models such as Flan-T5. (github.com)
Flan-UL2
Flan-UL2 is an encoder decoder model based on theT5architecture. It uses the same configuration as theUL2 modelreleased earlier last year. It was fine tuned using the "Flan" prompt tuning and dataset collection.
- Hugging Face: google/flan-ul2 · Hugging Face
- Review: Trying Out Flan 20B with UL2 — Working in Colab with 8Bit Inference — YouTube
GALACTICA (Meta)
Following Mitchell et al. (2018), this model card provides information about the GALACTICA model, how it was trained, and the intended use cases. Full details about how the model was trained and evaluated can be found in the release paper.
Here is a list of reproductions of or based on the GALACTICA project:
Galpaca
GALACTICA 30B fine-tuned on the Alpaca dataset.
- Hugging Face: GeorgiaTechResearchInstitute/galpaca-30b · Hugging Face
- Hugging Face: TheBloke/galpaca-30B-GPTQ-4bit-128g · Hugging Face
GLM (General Language Model)
GLM is a General Language Model pretrained with an autoregressive blank-filling objective and can be finetuned on various natural language understanding and generation tasks.
Here is a list of reproductions of or based on the GLM project:
ChatGLM2–6B (previously ChatGLM-6B)
ChatGLM2–6B is the second-generation version of the open-source bilingual (Chinese-English) chat model ChatGLM-6B. It retains the smooth conversation flow and low deployment threshold of the first-generation model.
GPT-J (EleutherAI)
GPT-J is an open source artificial intelligence language model developed by EleutherAI.[1] GPT-J performs very similarly to OpenAI’s GPT-3 on various zero-shot down-streaming tasks and can even outperform it on code generation tasks.[2] The newest version, GPT-J-6B is a language model based on a data set called The Pile.[3] The Pile is an open-source 825 gibibyte language modelling data set that is split into 22 smaller datasets.[4] GPT-J is similar to ChatGPT in ability, although it does not function as a chat bot, only as a text predictor.[5]
Here is a list of reproductions of or based on the GPT-J project:
Dolly (Databricks)
Databricks’ Dolly, a large language model trained on the Databricks Machine Learning Platform, demonstrates that a two-years-old open source model (GPT-J) can, when subjected to just 30 minutes of fine tuning on a focused corpus of 50k records (Stanford Alpaca), exhibit surprisingly high quality instruction following behavior not characteristic of the foundation model on which it is based. We believe this finding is important because it demonstrates that the ability to create powerful artificial intelligence technologies is vastly more accessible than previously realized.
- GitHub: databrickslabs/dolly: Databricks’ Dolly, a large language model trained on the Databricks Machine Learning Platform (github.com)
- Review: Meet Dolly the new Alpaca model — YouTube
GPT-J-6B instruction-tuned on Alpaca-GPT4
This model was finetuned on GPT-4 generations of the Alpaca prompts, using LoRA for 30.000 steps (batch size of 128), taking over 7 hours in four V100S.
- Hugging Face: vicgalle/gpt-j-6B-alpaca-gpt4 · Hugging Face
GPT4All-J
Demo, data, and code to train open-source assistant-style large language model based on GPT-J
- GitHub: nomic-ai/gpt4all: gpt4all: an ecosystem of open-source chatbots trained on a massive collections of clean assistant data including code, stories and dialogue (github.com)
- Review: GPT4ALLv2: The Improvements and Drawbacks You Need to Know! — YouTube
GPT-NeoX (EleutherAI)
This repository records EleutherAI’s library for training large-scale language models on GPUs. Our current framework is based on NVIDIA’s Megatron Language Model and has been augmented with techniques from DeepSpeed as well as some novel optimizations. We aim to make this repo a centralized and accessible place to gather techniques for training large-scale autoregressive language models, and accelerate research into large-scale training.
- GitHub: EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the DeepSpeed library. (github.com)
InternLM
We present InternLM, a multilingual foundational language model with 104B parameters. InternLM is pre-trained on a large corpora with 1.6T tokens with a multi-phase progressive process, and then fine-tuned to align with human preferences.InternLM is a multilingual large language model jointly developed by Shanghai AI Lab and SenseTime (with equal contribution), in collaboration with the Chinese University of Hong Kong, Fudan University, and Shanghai Jiaotong University.
- GitHub: InternLM (github.com)
h2oGPT (h2o.ai)
h2oGPT is a large language model (LLM) fine-tuning framework and chatbot UI with document(s) question-answer capabilities. Documents help to ground LLMs against hallucinations by providing them context relevant to the instruction. h2oGPT is fully permissive Apache V2 open-source project for 100% private and secure use of LLMs and document embeddings for document question-answer.
- GitHub: h2oai/h2ogpt: Come join the movement to make the world’s best open source GPT led by H2O.ai (github.com)
- Hugging Face: H2ogpt Oasst1 256 6.9b App — a Hugging Face Space by h2oai
HuggingGPT (Microsoft)
HuggingGPT is a collaborative system that consists of an LLM as the controller and numerous expert models as collaborative executors (from HuggingFace Hub).
Jais (G42)
Jais, the world’s highest quality Arabic Large Language Model. Jais is a 13-billion parameter model trained on a newly developed 395-billion-token Arabic and English dataset.
- Website: https://www.cerebras.net/press-release/meet-jais-the-worlds-most-advanced-arabic-large-language-model-open-sourced-by-g42s-inception
- Hugging Face: https://huggingface.co/inception-mbzuai
MPT (Mosaic ML)
MPT is a GPT-style model, and the first in the MosaicML Foundation Series of models. Trained on 1T tokens of a MosaicML-curated dataset, MPT is open-source, commercially usable, and equivalent to LLaMa on evaluation metrics. The MPT architecture contains all the latest techniques on LLM modeling — Flash Attention for efficiency, Alibi for context length extrapolation, and stability improvements to mitigate loss spikes. The base model and several variants, including a 64K context length fine-tuned model (!!) are all available.
- Website: Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs (mosaicml.com)
- GitHub: mosaicml/llm-foundry (github.com)
- Review: MPT-7B — The First Commercially Usable Fully Trained LLaMa Model — YouTube
- Hugging Face: mosaicml/mpt-30b · Hugging Face
- Hugging Face: mosaicml/mpt-30b-chat · Hugging Face
Here is a list of based on the MPT:
OpenFlamingo V2
Today, we are excited to release five trained OpenFlamingo models across the 3B, 4B, and 9B scales. These models are based on Mosaic’s MPT-1B and 7B and Together.xyz’s RedPajama-3B, meaning they are built on open-source models with less restrictive licenses than LLaMA. When averaging performance across 7 evaluation datasets, OpenFlamingo models attain more than 80% of the performance of their corresponding Flamingo model. OpenFlamingo-3B and OpenFlamingo-9B also attain more than 60% of fine-tuned SOTA performance using just 32 in-context examples.
- Website: OpenFlamingo v2: New Models and Enhanced Training Setup | LAION
- GitHub: mlfoundations/open_flamingo: An open-source framework for training large multimodal models. (github.com)
- Hugging Face: OpenFlamingo — a Hugging Face Space by openflamingo
NeMo — GPT-2B-001 (Nvidia)
GPT-2B-001 is a transformer-based language model. GPT refers to a class of transformer decoder-only models similar to GPT-2 and 3 while 2B refers to the total trainable parameter count (2 Billion) [1, 2]. This model was trained on 1.1T tokens with NeMo.
- Hugging Face: https://huggingface.co/nvidia/GPT-2B-001
OpenAssistant Models
Conversational AI for everyone.
- Website: Open Assistant (open-assistant.io)
- GitHub: LAION-AI/Open-Assistant: OpenAssistant is a chat-based assistant that understands tasks, can interact with third-party systems, and retrieve information dynamically to do so. (github.com)
- Hugging Face: OpenAssistant (OpenAssistant) (huggingface.co)
OpenLLaMA
In this repo, we release a permissively licensed open source reproduction of Meta AI’s LLaMA large language model. In this release, we’re releasing a public preview of the 7B OpenLLaMA model that has been trained with 200 billion tokens. We provide PyTorch and Jax weights of pre-trained OpenLLaMA models, as well as evaluation results and comparison against the original LLaMA models.We are releasing a 7B and 3B model trained on 1T tokens, as well as the preview of a 13B model trained on 600B tokens.
- GitHub: openlm-research/open_llama (github.com)
- Hugging Face: openlm-research (OpenLM Research) (huggingface.co)
PaLM (Google)
PaLM demonstrates the first large-scale use of the Pathways system to scale training to 6144 chips, the largest TPU-based system configuration used for training to date. The training is scaled using data parallelism at the Pod level across two Cloud TPU v4 Pods, while using standard data and model parallelism within each Pod. This is a significant increase in scale compared to most previous LLMs, which were either trained on a single TPU v3 Pod (e.g., GLaM, LaMDA), used pipeline parallelism to scale to 2240 A100 GPUs across GPU clusters (Megatron-Turing NLG) or used multiple TPU v3 Pods (Gopher) with a maximum scale of 4096 TPU v3 chips.
- Website: Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance — Google AI Blog (googleblog.com)
Here is a list of reproductions of or based on the PaLM project:
PaLM (Concept of Mind)
Introducing three new open-source PaLM models trained at a context length of 8k on C4. Open-sourcing LLMs is a necessity for the fair and equitable democratization of AI. The models of sizes 150m, 410m, and 1b are available to download and use here.
Palmyra Base (Writer)
Palmyra Base was primarily pre-trained with English text. Note that there is still a trace amount of non-English data present within the training corpus that was accessed through CommonCrawl. A causal language modeling (CLM) objective was utilized during the process of the model’s pretraining. Similar to GPT-3, Palmyra Base is a member of the same family of models that only contain a decoder. As a result, it was pre-trained utilizing the objective of self-supervised causal language modeling. Palmyra Base uses the prompts and general experimental setup from GPT-3 in order to conduct its evaluation per GPT-3.
- Hugging Face: Writer/palmyra-base · Hugging Face
Here is a list of reproductions of or based on the Palmyra Base project:
Camel 🐪 5B
Introducing Camel-5b, a state-of-the-art instruction-following large language model designed to deliver exceptional performance and versatility. Derived from the foundational architecture of Palmyra-Base, Camel-5b is specifically tailored to address the growing demand for advanced natural language processing and comprehension capabilities.
- Hugging Face: Writer/camel-5b-hf · Hugging Face
Polyglot (EleutherAI)
Large Language Models of Well-balanced Competence in Multi-languages. Various multilingual models such as mBERT, BLOOM, and XGLM have been released. Therefore, someone might ask, “why do we need to make multilingual models again?” Before answering the question, we would like to ask, “Why do people around the world make monolingual models in their language even though there are already many multilingual models?” We would like to point out there is a dissatisfaction with the non-English language performance of the current multilingual models as one of the most significant reason. So we want to make multilingual models with higher non-English language performance. This is the reason we need to make multilingual models again and why we name them ‘Polyglot’.
- GitHub: EleutherAI/polyglot: Polyglot: Large Language Models of Well-balanced Competence in Multi-languages (github.com)
PolyLM (Machine Translation Team at Alibaba DAMO Academy)
A multilingual LLM trained on 640 billion (B) tokens, avaliable in two model sizes: 1.7B and 13B. To enhance its multilingual capabilities, we 1) integrate bilingual data into training data; and 2) adopt a curriculum learning strategy that increases the proportion of non-English data from 30% in the first stage to 60% in the final stage during pre-training.
Hugging Face: https://huggingface.co/DAMO-NLP-MT/polylm-13b
Pythia (EleutherAI)
Interpreting Autoregressive Transformers Across Time and Scale
- GitHub: EleutherAI/pythia (github.com)
Here is a list of reproductions of or based on the Pythia project:
Dolly 2.0 (Databricks)
Dolly 2.0 is a 12B parameter language model based on the EleutherAI pythia model family and fine-tuned exclusively on a new, high-quality human generated instruction following dataset, crowdsourced among Databricks employees.
- Website: Free Dolly: Introducing the World’s First Open and Commercially Viable Instruction-Tuned LLM — The Databricks Blog
- Hugging Face: databricks (Databricks) (huggingface.co)
- GutHub: dolly/data at master · databrickslabs/dolly (github.com)
- Review: Dolly 2.0 by Databricks: Open for Business but is it Ready to Impress! — YouTube
RedPajama-INCITE 3B and 7B (Together)
The first models trained on the RedPajama base dataset: a 3 billion and a 7B parameter base model that aims to replicate the LLaMA recipe as closely as possible. In addition, we are releasing fully open-source instruction-tuned and chat models.
- Website: Releasing 3B and 7B RedPajama-INCITE family of models including base, instruction-tuned & chat models — TOGETHER
- Hugging Face: togethercomputer/RedPajama-INCITE-Base-3B-v1 · Hugging Face, togethercomputer/RedPajama-INCITE-Chat-3B-v1 · Hugging Face, and togethercomputer/RedPajama-INCITE-Instruct-3B-v1 · Hugging Face
- Hugging Face: togethercomputer/RedPajama-INCITE-Base-7B-v0.1 · Hugging Face, togethercomputer/RedPajama-INCITE-Chat-7B-v0.1 · Hugging Face, and togethercomputer/RedPajama-INCITE-Instruct-7B-v0.1 · Hugging Face
Replit-Code (Replit)
replit-code-v1-3bis a 2.7B Causal Language Model focused on Code Completion. The model has been trained on a subset of the Stack Dedup v1.2 dataset. The training mixture includes 20 different languages, listed here in descending order of number of tokens:Markdown,Java,JavaScript,Python,TypeScript,PHP,SQL,JSX,reStructuredText,Rust,C,CSS,Go,C++,HTML,Vue,Ruby,Jupyter Notebook,R,Shell
In total, the training dataset contains 175B tokens, which were repeated over 3 epochs -- in total,replit-code-v1-3bhas been trained on 525B tokens (~195 tokens per parameter).
- Hugging Face: https://huggingface.co/replit/replit-code-v1-3b
The RWKV Language Model
RWKV: Parallelizable RNN with Transformer-level LLM Performance (pronounced as “RwaKuv”, from 4 major params: R W K V)
- GitHub: BlinkDL/RWKV-LM
- ChatRWKV: with “stream” and “split” strategies and INT8. 3G VRAM is enough to run RWKV 14B :) https://github.com/BlinkDL/ChatRWKV
- Hugging Face Demo: HuggingFace Gradio demo (14B ctx8192)
- Hugging Face Demo: Raven (7B finetuned on Alpaca) Demo
- RWKV pip package: https://pypi.org/project/rwkv/
- Review: Raven — RWKV-7B RNN’s LLM Strikes Back — YouTube
Segment Anything (Meta)
The Segment Anything Model (SAM) produces high quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image. It has been trained on a dataset of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.
- Website: Introducing Segment Anything: Working toward the first foundation model for image segmentation (facebook.com)
- GitHub: facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. (github.com)
StableLM (StabilityAI)
A new open-source language model, StableLM. The Alpha version of the model is available in 3 billion and 7 billion parameters, with 15 billion to 65 billion parameter models to follow. Developers can freely inspect, use, and adapt our StableLM base models for commercial or research purposes, subject to the terms of the CC BY-SA-4.0 license. StableLM is trained on a new experimental dataset built on The Pile, but three times larger with 1.5 trillion tokens of content. We will release details on the dataset in due course. The richness of this dataset gives StableLM surprisingly high performance in conversational and coding tasks, despite its small size of 3 to 7 billion parameters (by comparison, GPT-3 has 175 billion parameters)
- Website: Stability AI Launches the First of its StableLM Suite of Language Models — Stability AI
- GitHub: Stability-AI/StableLM: StableLM: Stability AI Language Models (github.com)
- Hugging Face: Stablelm Tuned Alpha Chat — a Hugging Face Space by stabilityai
- Review: Stable LM 3B — The new tiny kid on the block. — YouTube
StartCoder (BigCode)
BigCode is an open scientific collaboration working on responsible training of large language models for coding applications. You can find more information on the main website or follow Big Code on Twitter. In this organization you can find the artefacts of this collaboration: StarCoder, a state-of-the-art language model for code, The Stack, the largest available pretraining dataset with perimssive code, and SantaCoder, a 1.1B parameter model for code.
- Website: https://huggingface.co/bigcode
- Hugging Face: https://huggingface.co/spaces/bigcode/bigcode-editor and https://huggingface.co/spaces/bigcode/bigcode-playground
- Review: Testing Starcoder for Reasoning with PAL — YouTube
TigerBot (Tiger Research)
A cutting-edge foundation for your very own LLM.
- Website: https://tigerbot.com/
- Hugging Face: https://huggingface.co/TigerResearch/tigerbot-7b-sft-v2
- GitHub: https://github.com/TigerResearch/TigerBot
XGen (Salesforce)
Long Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length. We trained a series of 7B LLMs named XGen-7B with standard dense attention on up to 8K sequence length for up to 1.5T tokens. We also fine tune the models on public-domain instructional data. The main take-aways are:On standard NLP benchmarks, XGen achieves comparable or better results when compared with state-of-the-art open-source LLMs (e.g. MPT, Falcon, LLaMA, Redpajama, OpenLLaMA) of similar model size.Our targeted evaluation on long sequence modeling benchmarks show benefits of our 8K-seq models over 2K- and 4K-seq models.XGen-7B archives equally strong results both in text (e.g., MMLU, QA) and code (HumanEval) tasks.Training cost of $150K on 1T tokens under Google Cloud pricing for TPU-v4.
- Website: Long Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length (salesforceairesearch.com)
- GitHub: salesforce/xgen: Salesforce open-source LLMs with 8k sequence length. (github.com)
- Hugging Face: Salesforce/xgen-7b-8k-base · Hugging Face
XGLM (Meta)
The XGLM model was proposed in Few-shot Learning with Multilingual Language Models.
- GitHub: https://github.com/facebookresearch/fairseq/tree/main/examples/xglm
- Hugging Face: https://huggingface.co/docs/transformers/model_doc/xglm
Other Repositories
A’eala
- Hugging Face: Aeala (A’eala) (huggingface.co)
Augustin Toma
- Hugging Face: https://huggingface.co/augtoma
ausboss
- Hugging Face: https://huggingface.co/ausboss
Benjamin Anderson
- Hugging Face: andersonbcdefg (Benjamin Anderson) (huggingface.co)
- Hugging Face: https://huggingface.co/CalderaAI
CarperAI
- Hugging Face: CarperAI (CarperAI) (huggingface.co)
chavinlo
- Hugging Face: chavinlo (Chavez) (huggingface.co)
chainyo
- Hugging Face: chainyo (Thomas Chaigneau) (huggingface.co)
ClimateBert
Concept of Mind
couchpotato888
- Hugging Face: couchpotato888 (Phil Wee) (huggingface.co)
crumb
- Hugging Face: https://huggingface.co/crumb
Daniel Furman
- Hugging Face: https://huggingface.co/dfurman
DeepNight Research Nexus
- Hugging Face: https://huggingface.co/deepnight-research
digitous
- Hugging Face: digitous (Erik) (huggingface.co)
eachadea
- Hugging Face: eachadea (eachadea) (huggingface.co)
elinas
- Hugging Face: elinas (elinas) (huggingface.co)
Eric Hartford
- Hugging Face: ehartford (Eric Hartford) (huggingface.co)
Eugene Pentland
- Hugging Face: eugenepentland (Eugene Pentland) (huggingface.co)
FlashVenom
- Hugging Face: flashvenom (FlashVenom) (huggingface.co)
Francisco Jaque
- Hugging Face: Panchovix (Francisco Jaque) (huggingface.co)
Frank Zhao
- Hugging Face: https://huggingface.co/fangloveskari
bAInd
- Hugging Face: https://huggingface.co/garage-bAInd
Georgia Tech Research Institute
Huggy Llama
- Hugging Face: https://huggingface.co/huggyllama
Jon Durbin
- Hugging Face: jondurbin (Jon Durbin) (huggingface.co)
Knut Jägersberg
- Hugging Face: https://huggingface.co/KnutJaegersberg
KoboldAI
- Hugging Face: KoboldAI (KoboldAI) (huggingface.co)
LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
LaMini-LM is a collection of small-sized, efficient language models distilled from ChatGPT and trained on a large-scale dataset of 2.58M instructions. We explore different model architectures, sizes, and checkpoints, and extensively evaluate their performance across various NLP benchmarks and through human evaluation.
- Paper: [2304.14402] LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions (arxiv.org)
- GitHub: mbzuai-nlp/LaMini-LM: LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions (github.com)
- Review: LaMini-LM — Mini Models Maxi Data! — YouTube
LLMs
Manuel Romero
- Hugging Face: mrm8488 (Manuel Romero) (huggingface.co)
MetaIX
- Hugging Face: https://huggingface.co/MetaIX
Michael
- Hugging Face: michaelfeil (Michael) (huggingface.co)
OpenOrca
- Hugging Face: https://huggingface.co/Open-Orca
OptimalScale
- Hugging Face: OptimalScale (OptimalScale) (huggingface.co)
Pankaj Mathur
- Hugging Face: psmathur (Pankaj Mathur) (huggingface.co)
pinkmanlove
- Hugging Face: https://huggingface.co/pinkmanlove
- Hugging Face: https://huggingface.co/project-baize
quantumai.kr
- Hugging Face: https://huggingface.co/quantumaikr
Seonghyeon Ye
- Hugging Face: https://huggingface.co/seonghyeonye
Sahil Chaudhary
- Hugging Face: sahil2801 (Sahil Chaudhary) (huggingface.co)
Teknium
- Hugging Face: https://huggingface.co/teknium
Tencent Music Entertainment Lyra Lab
theblackcat102
- Hugging Face: theblackcat102 (theblackcat102) (huggingface.co)
Tiger Research
- Hugging Face: TigerResearch (Tiger Research) (huggingface.co)
Tim Dettmers
- Hugging Face: timdettmers (Tim Dettmers) (huggingface.co)
I hope you have enjoyed this article. If you have any questions or comments, please provide them here.
List of all Foundation Models
Sourced from: A List of 1 Billion+ Parameter LLMs (matt-rickard.com)
- GPT-J (6B) (EleutherAI)
- GPT-Neo (1.3B, 2.7B, 20B) (EleutherAI)
- Pythia (1B, 1.4B, 2.8B, 6.9B, 12B) (EleutherAI)
- Polyglot (1.3B, 3.8B, 5.8B) (EleutherAI)
- J1/Jurassic-1 (7.5B, 17B, 178B) (AI21)
- J2/Jurassic-2 (Large, Grande, and Jumbo) (AI21)
- LLaMa (7B, 13B, 33B, 65B) (Meta)
- OPT (1.3B, 2.7B, 13B, 30B, 66B, 175B) (Meta)
- Fairseq (1.3B, 2.7B, 6.7B, 13B) (Meta)
- GLM-130B YaLM (100B) (Yandex)
- YaLM (100B) (Yandex)
- UL2 20B (Google)
- PanGu-α (200B) (Huawei)
- Cohere (Medium, XLarge)
- Claude (instant-v1.0, v1.2) (Anthropic)
- CodeGen (2B, 6B, 16B) (Salesforce)
- NeMo (1.3B, 5B, 20B) (NVIDIA)
- RWKV (14B)
- BLOOM (1B, 3B, 7B)
- GPT-4 (OpenAI)
- GPT-3.5 (OpenAI)
- GPT-3 (ada, babbage, curie, davinci) (OpenAI)
- Codex (cushman, davinci) (OpenAI)
- T5 (11B) (Google)
- CPM-Bee (10B)
- Cerebras-GPT
Resources
- PRIMO.ai Large Language Model (LLM): https://primo.ai/index.php?title=Large_Language_Model_(LLM)
- A Survey of Large Language Models: [2303.18223] A Survey of Large Language Models (arxiv.org)
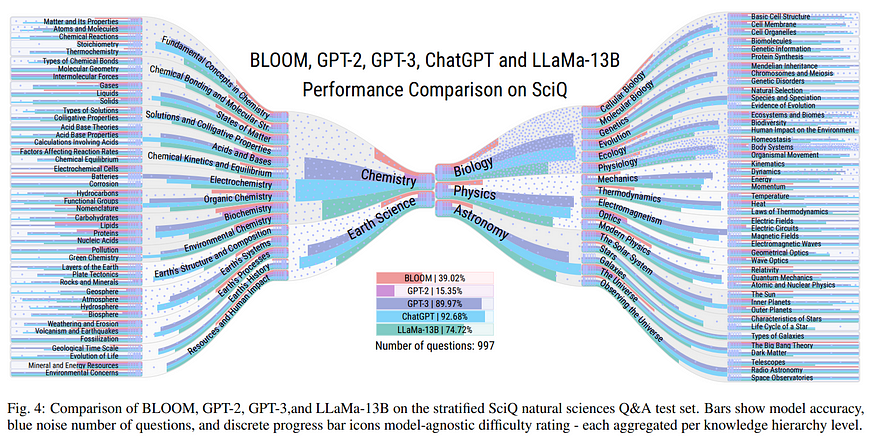
- LLMMaps — A Visual Metaphor for Stratified Evaluation of Large Language Models: https://arxiv.org/abs/2304.00457
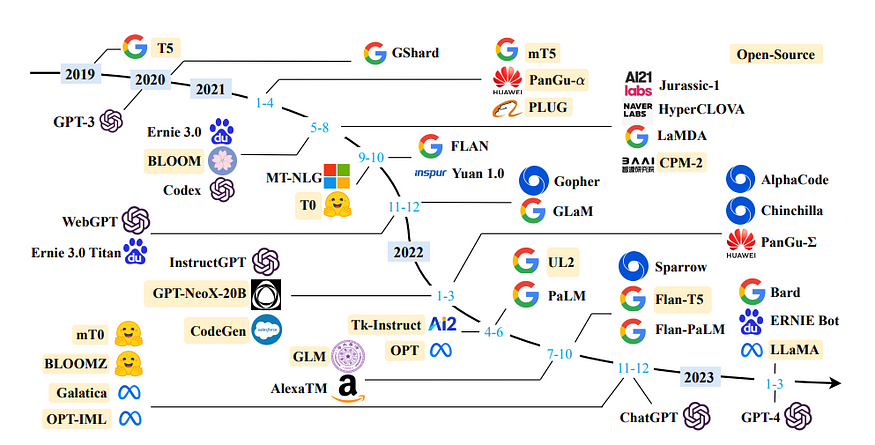
- A brief history of LLaMA models (A brief history of LLaMA models — AGI Sphere (agi-sphere.com))
- Google “We Have No Moat, And Neither Does OpenAI” (https://www.semianalysis.com/p/google-we-have-no-moat-and-neither)
- Chatbot Arena (Chat with Open Large Language Models (lmsys.org))
- Ahead of AI #8: The Latest Open Source LLMs and Datasets
- Open LLM Leaderboard (Open LLM Leaderboard — a Hugging Face Space by HuggingFaceH4)
- AlpacaEval Leaderboard (Alpaca Eval Leaderboard (tatsu-lab.github.io)
- LLMSurvey (RUCAIBox/LLMSurvey: The official GitHub page for the survey paper “A Survey of Large Language Models”.)
- Open LLM-Perf Leaderboard (Open LLM-Perf Leaderboard — a Hugging Face Space by optimum)
- MT-Bench Leaderboard (Chat with Open Large Language Models (lmsys.org))
- A Survey on Multimodal Large Language Models ([2306.13549] A Survey on Multimodal Large Language Models (arxiv.org))
взято отсюда https://sungkim11.medium.com/list-of-open-sourced-fine-tuned-large-language-models-llm-8d95a2e0dc76